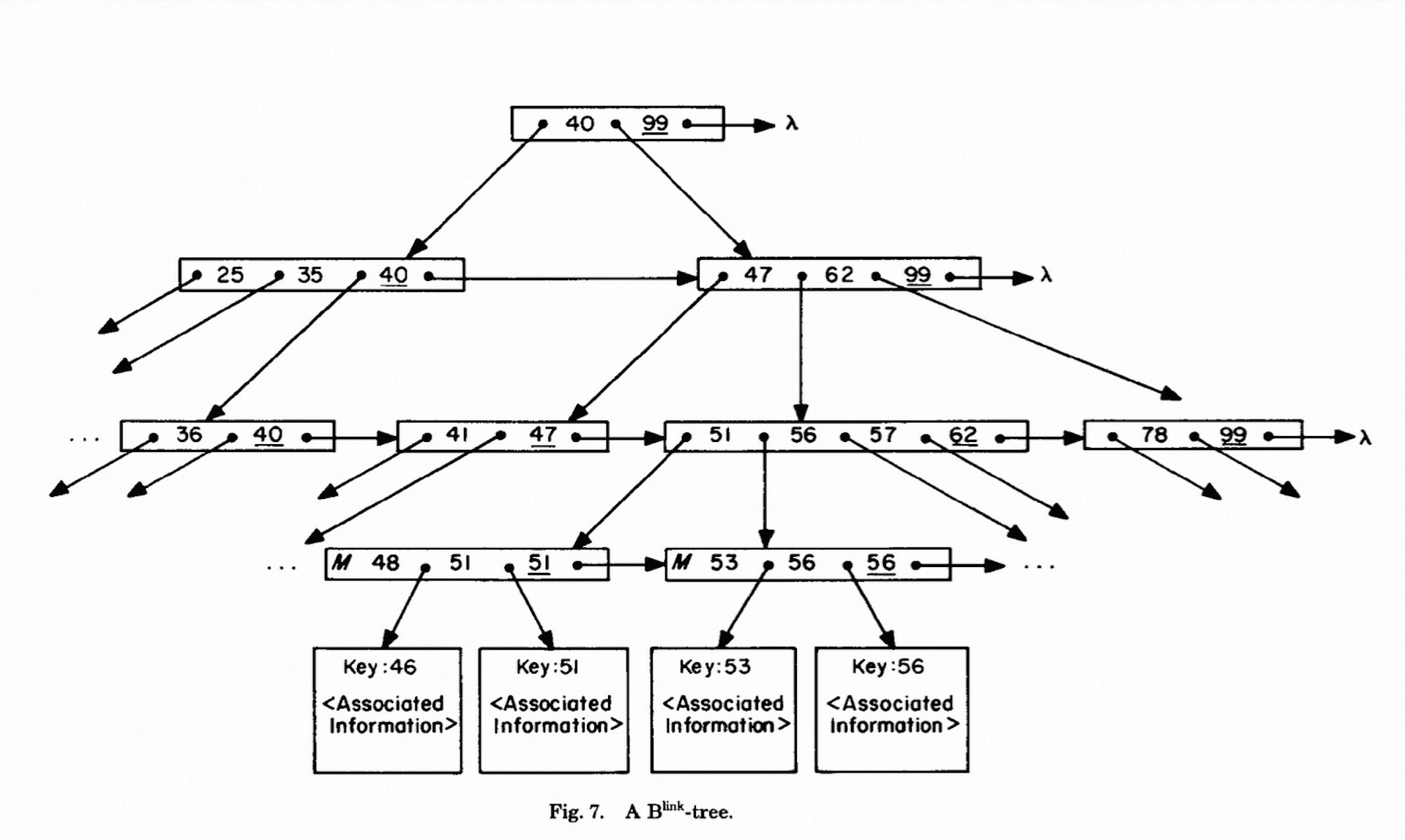
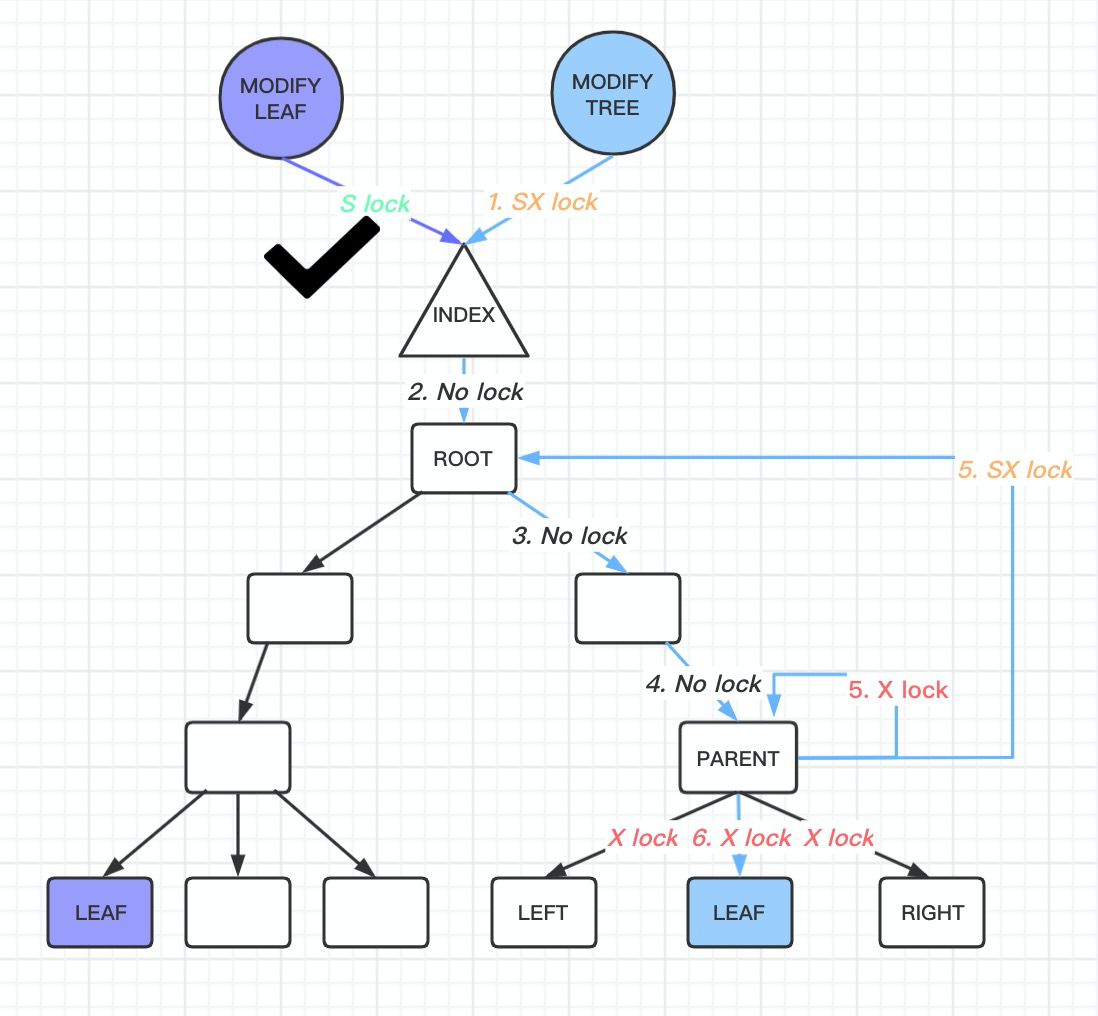
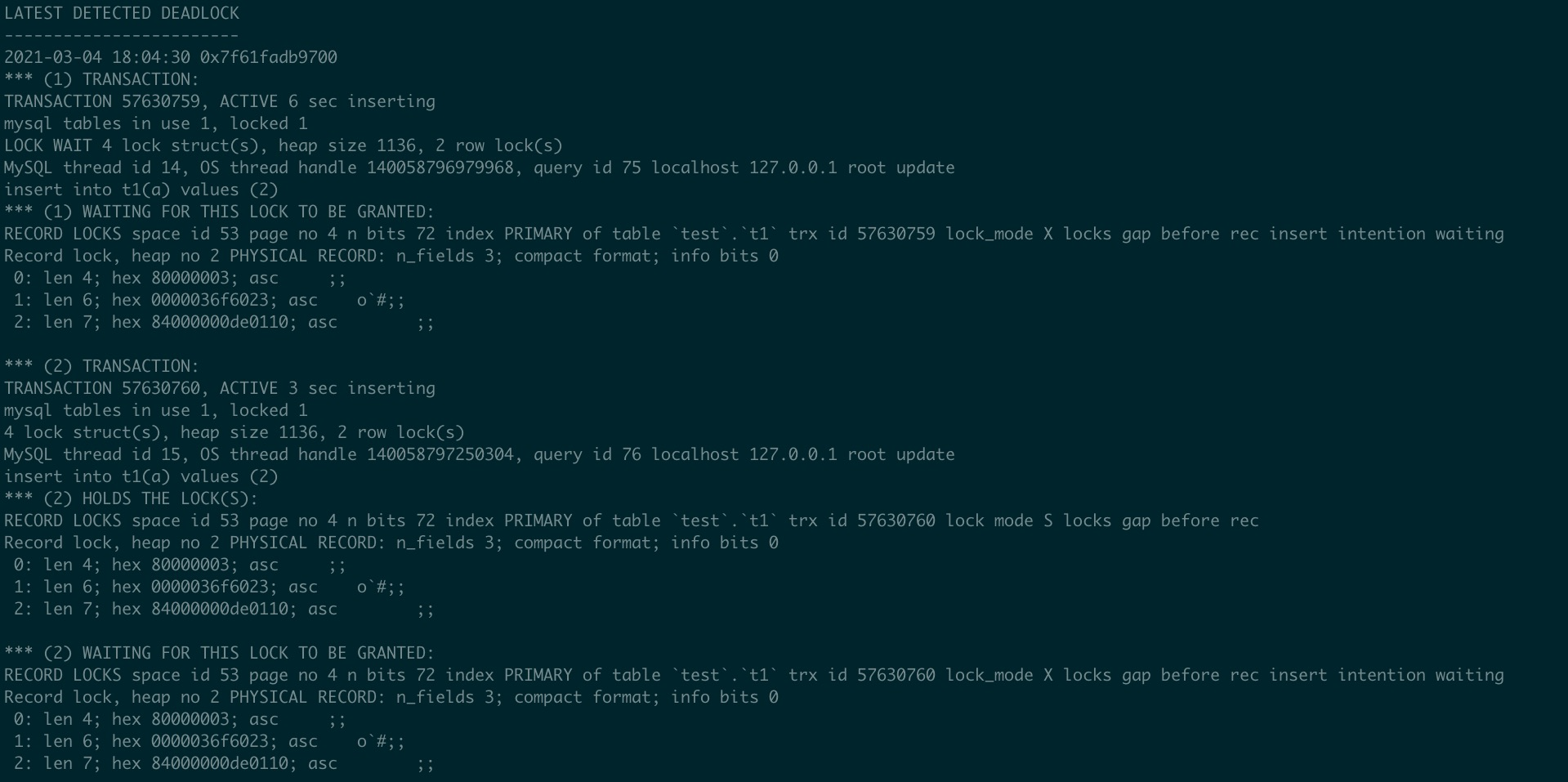
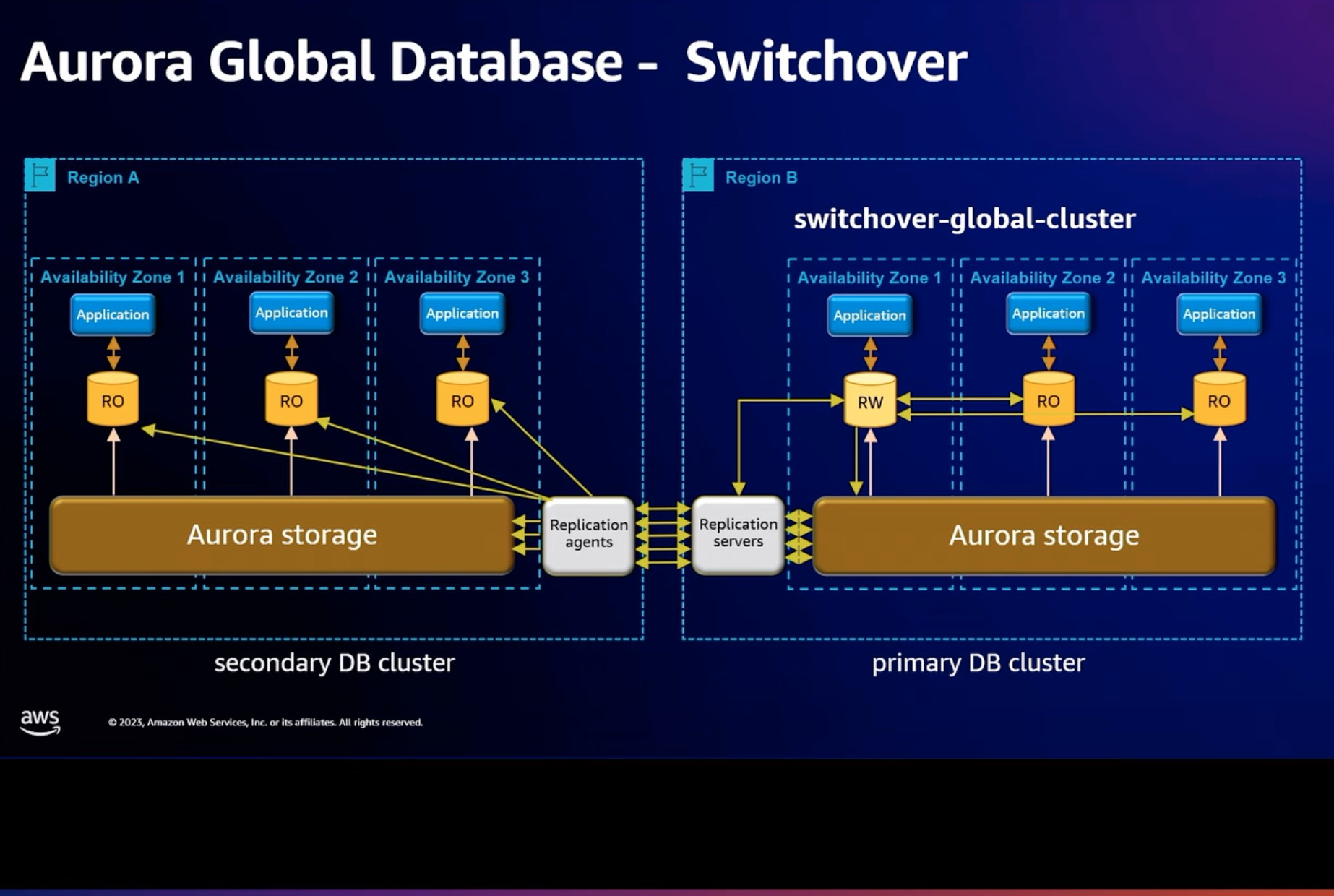
In reality, the B-tree is a very flat structure. Most B-trees do not exceed 4 levels. Let’s examine this with an example of a common sysbench table:
CREATE TABLE `sbtest1` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=10958 DEFAULT CHARSET=latin1;
In InnoDB, there are two main types of pages: leaf pages and non-leaf pages.
The format of the leaf page is as follows: each record mainly consists of a Record Header and a Record Body. The Record Header is primarily used in conjunction with DD (data dictionary) information to support the Record Body. The Record Body contains the main content of the record.
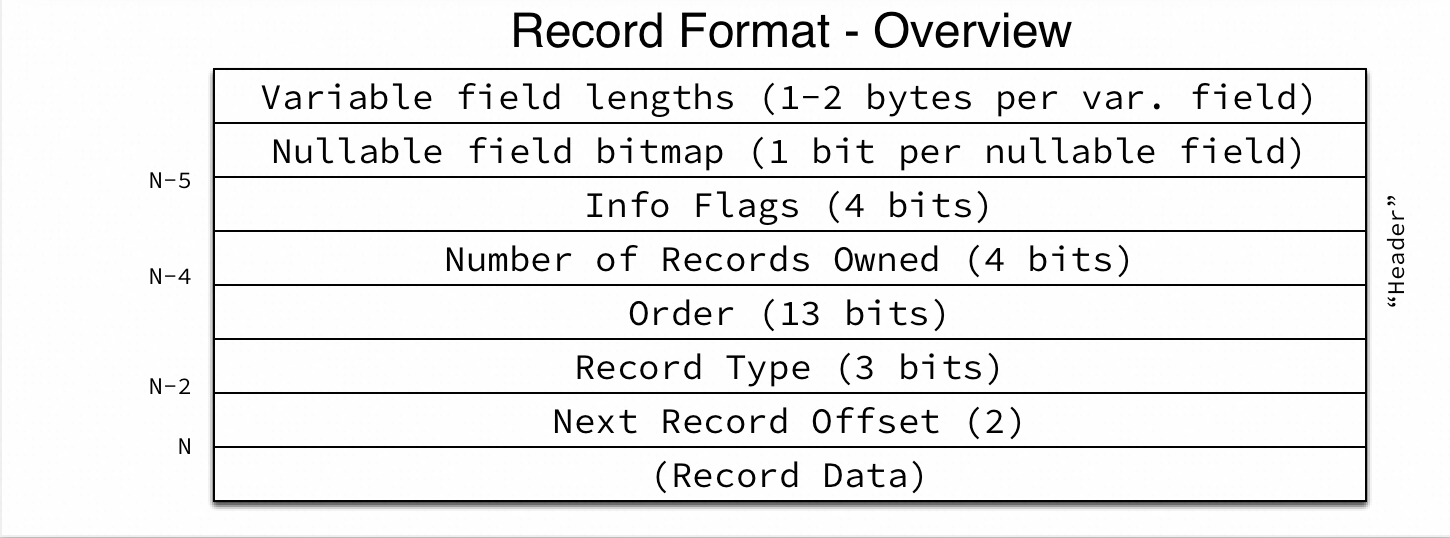

In a 16KB page of a sysbench-like table, the approximate number of rows that can be stored in a leaf page is calculated as:
(16 * 1024 - 200 (for the page header, tail, and directory slot length)) / ((4 + 4 + 120 + 60) (row data length) + 5 (row header) + 6 (Transaction ID) + 7 (Roll Pointer)) = 78.5 rows
The format of the non-leaf page is as follows:
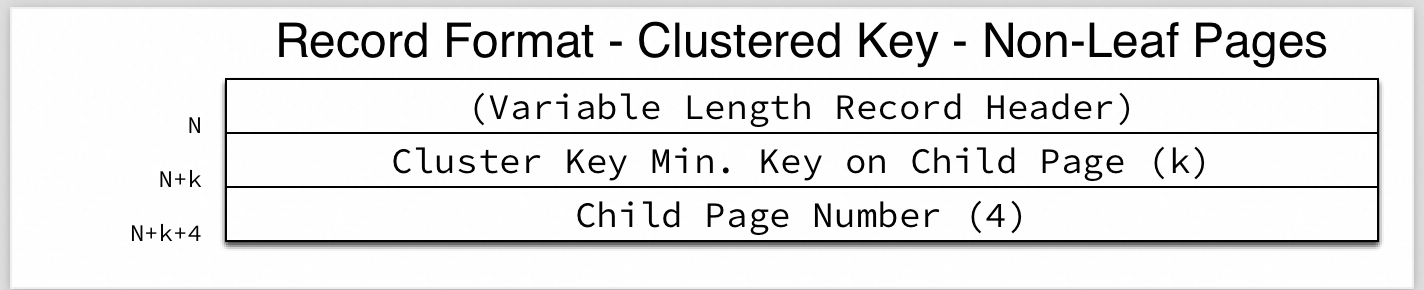
Since the sysbench primary key id is an integer (4 bytes), the number of rows that can be stored in a 16KB page is calculated as:
(16 * 1024 - 200) / (5 (row header) + 4 (cluster key) + 4 (child page number)) = 1233 rows
The following table shows the height and size of a B-tree at different levels:
| Height | Non-leaf Pages | Leaf Pages | Rows | Size |
|---|---|---|---|---|
| 1 | 0 | 1 | 79 | 16KB |
| 2 | 1 | 1233 | 97,407 | 19MB |
| 3 | 1234 | 1,520,289 | 120,102,831 | 23GB |
| 4 | 1,521,523 | 1,874,516,337 | 148,086,790,623 | 27.9TB |
From the above, we can see that for a sysbench-like table with 140 billion rows and a size of 27.9TB, the B-tree height does not exceed 4 levels. Therefore, you do not need to worry about performance issues caused by B-tree height, even with large datasets.
Impact of Using BIGINT as the Primary Key
If the primary key is changed to BIGINT (8 bytes), the number of rows per leaf page changes slightly:
(16 * 1024 - 200) / ((8 + 4 + 120 + 60) + 13) = 78.9 rows
The number of rows in non-leaf pages changes as well:
(16 * 1024 - 200) / (5 + 8 + 4) = 952 rows
| Height | Non-leaf Pages | Leaf Pages | Rows | Size |
|---|---|---|---|---|
| 1 | 0 | 1 | 79 | 16KB |
| 2 | 1 | 952 | 75,208 | 15MB |
| 3 | 953 | 906,304 | 71,598,016 | 13.8GB |
| 4 | 907,257 | 862,801,408 | 68,161,311,232 | 12.8TB |
After switching to BIGINT, a four-level B-tree can store 60 billion rows and about 12TB of data.
Example of a More Complex Table (Polarbench)
For more complex tables, such as those used in SaaS scenarios, we use the following structure:
CREATE TABLE `prefix_off_saas_log_10` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`saas_type` varchar(64) DEFAULT NULL,
`saas_currency_code` varchar(3) DEFAULT NULL,
`saas_amount` bigint(20) DEFAULT '0',
`saas_direction` varchar(2) DEFAULT 'NA',
`saas_status` varchar(64) DEFAULT NULL,
`ewallet_ref` varchar(64) DEFAULT NULL,
`merchant_ref` varchar(64) DEFAULT NULL,
`third_party_ref` varchar(64) DEFAULT NULL,
`created_date_time` datetime DEFAULT NULL,
`updated_date_time` datetime DEFAULT NULL,
`version` int(11) DEFAULT NULL,
`saas_date_time` datetime DEFAULT NULL,
`original_saas_ref` varchar(64) DEFAULT NULL,
`source_of_fund` varchar(64) DEFAULT NULL,
`external_saas_type` varchar(64) DEFAULT NULL,
`user_id` varchar(64) DEFAULT NULL,
`merchant_id` varchar(64) DEFAULT NULL,
`merchant_id_ext` varchar(64) DEFAULT NULL,
`mfg_no` varchar(64) DEFAULT NULL,
`rfid_tag_no` varchar(64) DEFAULT NULL,
`admin_fee` bigint(20) DEFAULT NULL,
`ppu_type` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `saas_log_idx01` (`user_id`) USING BTREE,
KEY `saas_log_idx02` (`saas_type`) USING BTREE,
KEY `saas_log_idx03` (`saas_status`) USING BTREE,
KEY `saas_log_idx04` (`merchant_ref`) USING BTREE,
KEY `saas_log_idx05` (`third_party_ref`) USING BTREE,
KEY `saas_log_idx08` (`mfg_no`) USING BTREE,
KEY `saas_log_idx09` (`rfid_tag_no`) USING BTREE,
KEY `saas_log_idx10` (`merchant_id`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8
Since this table contains variable-length fields, and most references are assumed to have values, let’s assume all varchar fields are fully used.
When we add up all these fields, including the extra space for the Record Header, it comes to approximately 974 bytes per record.
Therefore, the number of records that can be stored in a leaf page is:
(16 * 1024 - 200) / 974 = 16.6 rows
For non-leaf pages, the capacity is similar to the sysbench table.
| Height | Non-leaf Pages | Leaf Pages | Rows | Size |
|---|---|---|---|---|
| 1 | 0 | 1 | 16 | 16KB |
| 2 | 1 | 952 | 15,232 | 15MB |
| 3 | 953 | 906,304 | 14,500,864 | 13.8GB |
| 4 | 907,257 | 862,801,408 | 13,804,822,528 | 12.8TB |
It can be seen that even for a table where each row is about 1KB, if the primary key is still BIGINT, the B-tree height remains within 4 levels for data sizes under 10TB, allowing the table to store about 13.8 billion rows.
Thus, storing tens of billions of rows in MySQL is not an issue.
MySQL best practices suggest avoiding UUIDs as primary keys.
For example, if the primary key of the prefix_off_saas_log_10 table is changed to a 32-byte UUID, the number of records that can be stored in a non-leaf page is:
(16 * 1024 - 200) / (5 + 32 + 4) = 394 rows
| Height | Non-leaf Pages | Leaf Pages | Rows | Size |
|---|---|---|---|---|
| 1 | 0 | 1 | 16 | 16KB |
| 2 | 1 | 394 | 6,304 | 6MB |
| 3 | 395 | 155,236 | 2,483,776 | 2GB |
| 4 | 155,631 | 61,162,984 | 978,607,744 | 981GB |
| 5 | 61,318,615 | 24,098,215,696 | 385,571,451,136 | 386TB |
From the table above, we can see that if UUID is used as the primary key, the same four-level B-tree can store 970 million rows, while using BIGINT can store 13.8 billion rows. However, even if UUID is mistakenly used as the primary key, the depth of MySQL’s B-tree will not exceed five levels, capable of storing up to 3.8 trillion rows and 386TB of data. This is unrealistic, as MySQL supports a maximum of 64TB per table.
Conclusion
In general, there’s no need to worry about increased B-tree height impacting performance as the data size grows. For tables under 10TB, the B-tree height will always be within four levels, and even above 10TB, it will remain at five levels because MySQL tables have a maximum size of 64TB.
PolarDB supports many large tables online, with plenty of tables exceeding 10TB. I’ve also seen real-world cases shared by DBAs from major companies, like Weibo’s “6B” brother, who talked about a single Weibo table with 6 billion rows. The founder of NineData shared examples from overseas WeChat-like businesses handling tens of billions of rows in a single table, and these run just fine. So, if the table structure is designed reasonably, large tables are completely manageable, and there’s no need to be misled by current database vendors.
]]>