为什么游戏行业喜欢用PolarDB
游戏行业痛点
在我看来, 不同行业对数据库使用有巨大的差别. 比如游戏行业没有复杂的事务交易场景, 他有一个非常大的blob 字段用于存储角色的装备信息, 那么大Blob 字段的更新就会成为数据库的瓶颈, 比如在线教育行业需要有抢课的需求, 因此会有热点行更新的场景, 对热点行如何处理会成为数据库的瓶颈, 比如SaaS 行业, 每一个客户有一个Database, 因此会有非常多的Table, 那么数据库就需要对多表有很好的支持能力.
游戏行业和其他行业对数据库的使用要求是不一样的.
所以在支撑了大量游戏业务之后, 我理解游戏行业在使用自建MySQL 的时候有3个比较大的痛点
- 对备份恢复的需求
- 对写入性能的要求
- 对跨region 容灾的需求
接下来会分别讲述这三个痛点PolarDB 是如何解决的.
备份恢复
笔者和大量游戏开发者沟通中, 游戏行业对备份恢复的需求是极其强烈的. 比如在电商行业, 是不可能存在将整个数据库实例进行回滚到一天之前的数据, 这样所有的用户的购买交易信息都丢失了.
但是, 在游戏行业中, 这种场景确实存在的, 比如在发版的时候, 游戏行业是有可能发版失败, 这个在其他行业出现概率非常低, 如果发版失败, 那么整个实例就需要回滚到版本之前. 因此每次发版的时候都需要对数据库实例进行备份. 因此当我们玩游戏的时候, 看到大版本需要停服更新, 那么就有可能是因为后台需要备份数据等等一系列操作了.
还有一种场景, 当发生因为外挂, 漏洞, 参数配置错误等等场景下, 这种紧急情况游戏就需要回滚到出问题前的版本, 这样就需要对整个实例进行回滚.
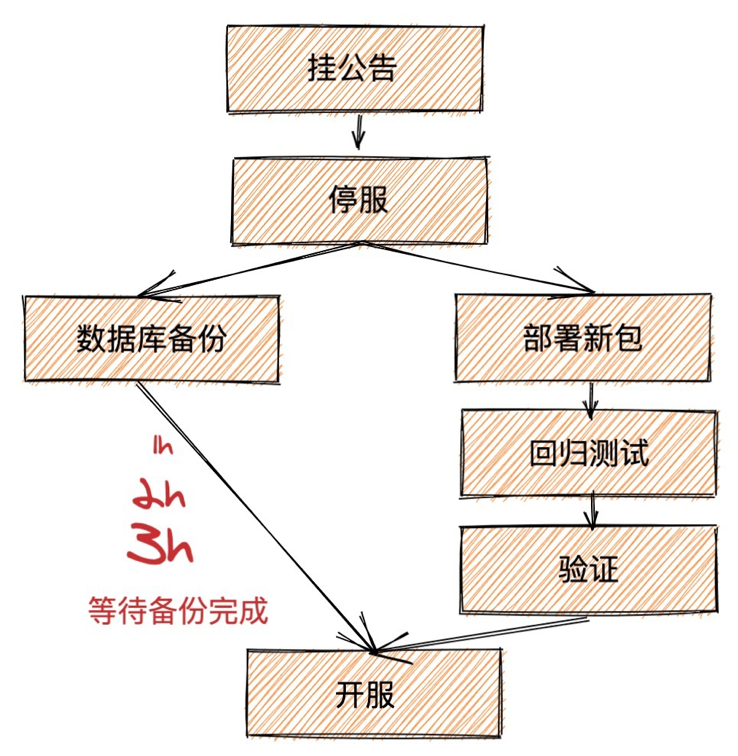
官方MySQL 由于是单机架构, 那么常见的备份方法是通过Xtrabackup 工具, 将数据备份到本地以后, 如果本地空间不够, 就需要上传到OSS 等远端存储中. 通常通过Xtrabackup 备份工具都需要1h 左右, 如果需要将数据上传到远端那么时间就更长了.
PolarDB 是天然的计存分离的架构, 那么备份的时候通过底下分布式存储的快照能力, 备份可以不超过30s, 将备份时间大大缩短了.
核心思路是采用Redirect-on-Write 机制, 每次创建快照并没有真正Copy数据, 只有建立快照索引, 当数据块后期有修改(Write)时才把历史版本保留给Snapshot, 然后生成新的数据块, 被原数据引用(Redirect).
另外一种场景是, 在游戏行业中, 有可能某一个玩家的装备被盗号了, 那么玩家就会找游戏的运营人员投诉, 运营人员会找到游戏运维人员, 帮忙查询玩家的历史数据.
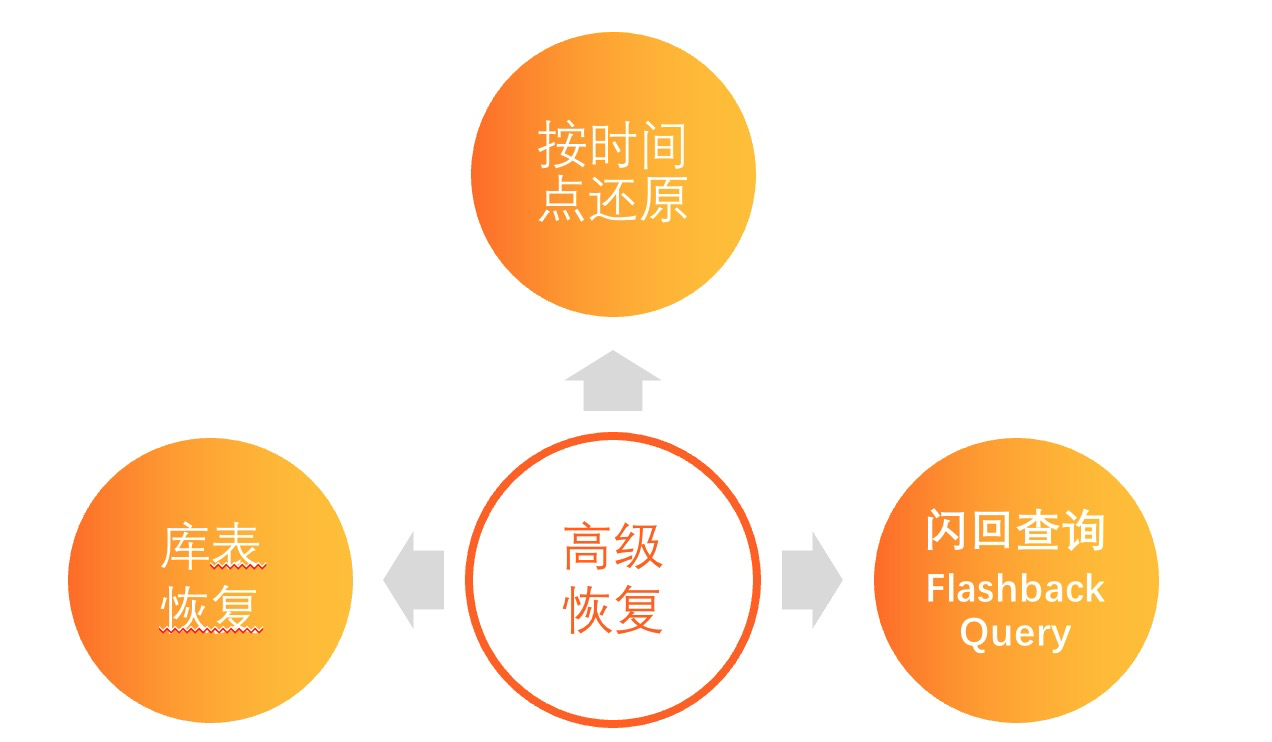
笔者之前就遇到某著名游戏多个玩家被盗号, 然后运维人员经常需要通过PolarDB 按时间的还原的能力恢复出某多个不同时间点的实例, 用来查询这个玩家的具体装备信息, 同时由于玩家对盗号的时间也不准确, 经常有时候需要还原出多个实例才可以.
针对这样的场景, PolarDB 推出了Flashback Query, 就可以在当前实例查询出任意时间点的历史数据. 具体原理见文章 Flashback Query

整体而言, PolarDB 建立了一套非常完善的备份恢复能力, 从库=>表=>行三个维度满足的游戏行业对备份恢复的需求.
写入性能
游戏行业使用数据库的方式也与其他行业有较大区别, 是一种非常弱Schema 的使用方式, 其他行业通常对业务经常抽象, 建立表结构, 每个字段尽可能小, 不建议有大字段, 有大字段尽可能进行拆封等等.
但是在游戏行业中, 由于需要满足游戏快速迭代发展的需求, 玩家的装备信息结构非常复杂, 因此常见的做法是将玩家装备等级信息保存在一个大的blob字段中, 这个blob字段通过proto_buf 或者 json 进行编解码, 每次在获得装备或者升级以后, 就进行整个字段更新, 在游戏开服初期玩家数据长度较短, 而随着游戏版本更新版本, 游戏剧情, 运营活动的增多, 相对于游戏开服初期的数KB, blob字段的长度可能会膨胀到数百KB, 甚至达到MB级别, 因此可能只是获得一个装备, 就需要向数据库写入数百KB 大小的数据, 这样的写放大其实非常不合理.
目前也有像MongoDB 这样的文档数据库, 让用户写入的时候仅仅更新某个字段, 从而减少写放大. 但是这样影响了用户的使用习惯, 需要用户在业务逻辑上进行修改, 这是快速发展的游戏行业所不能接受的, 所以笔者看到尽管有客户因为写入问题转向了MongoDB, 但是其实不多.
PolarDB 针对这样的情况尽可能满足用户的使用习惯, 在数据库内核层面优化数据库的写入能力. 通过 partition redo log, redo log cache, undo log readahead, early lock release, no blob latch 等等能力将写入能力充分优化. 具体原理可以参考我们内核月报 和之前的文章PolarDB-cloudjump
针对游戏场景, 我们修改了 sysbench 工具, 模拟游戏行业中大Blob 更新的workload, 放在 game-sysbench 工具中, 后续我们还会将更多行业比如Saas, 电商等等行业的workload 放在这个工具中.
在game_blob_update workload 中, 如果玩家的平均装备信息是 300kb, 我们对比了PolarDB VS aurora VS 自建MySQL 的数据
PolarDB 8.0 相对有最高的QPS 1877.44, 峰值QPS最高可以到2000, CPU bound场景PolarDB的性能大概是Aurora的5.7倍, 是自建 MySQL 本地盘的3倍. IO bound场景PolarDB的性能是Aurora的15倍.
CPU bound场景:
| DB | 并发数据 | QPS |
|---|---|---|
| PolarDB 8.0 | 5 | 1877.44 |
| MySQL 8.0 本地盘 | 4 | 600.22 |
| Aurora 8.0 | 200 | 328.47 |
IO bound场景:
| DB | 并发数据 | QPS |
|---|---|---|
| PolarDB 8.0 | 200 | 1035.30 |
| MySQL 8.0 本地盘 | 200 | 610 |
| Aurora 8.0 | 200 | 69.15 |
跨region 容灾
目前游戏行业纷纷出海, 包含了游戏服和平台服. 用户在自建MySQL/RDS 的场景中, 用户可能需要在另外一个region 建立一个新的实例, 然后通过同步工具或者DTS 进行跨region 备份. 用户需要处理region 错误场景如何进行切换等等.
笔者认为对数据库而言, 稳定性 > 易用性 > 性能.
在这个场景中, 用户如果使用云厂商的话, 使用的是云厂商提供的原子能力, 自己通过组装这些原子能力实现容灾的需求, 而PolarDB 针对这样场景提出来PolarDB GlobalDataba 的解决方案, 将跨region 的容灾放在解决方案中, 提供了一个更加易容的解决方案, 从而用户可以关注自身的业务逻辑, 而不需要处理这些容灾的场景.
在具体跨region 的同步场景方案中, PolarDB 是通过多通道物理复制能力, 从而保证跨region 的容灾在1s 以内.