PolarDB 物理复制SMO 同步机制
问题背景:
sync_counter 这个东西引入 主要解决这个问题这个场景的问题.
如果一个mtr 里面修改了多个page(最常见的场景就是 btree split/merge 的场景), 这个时候如果在replica 上面有一个search 操作, 那么会存在search 到某一个page 的时候, 这个page 指向的next_page 是不对的这样的场景.
如下图所示:
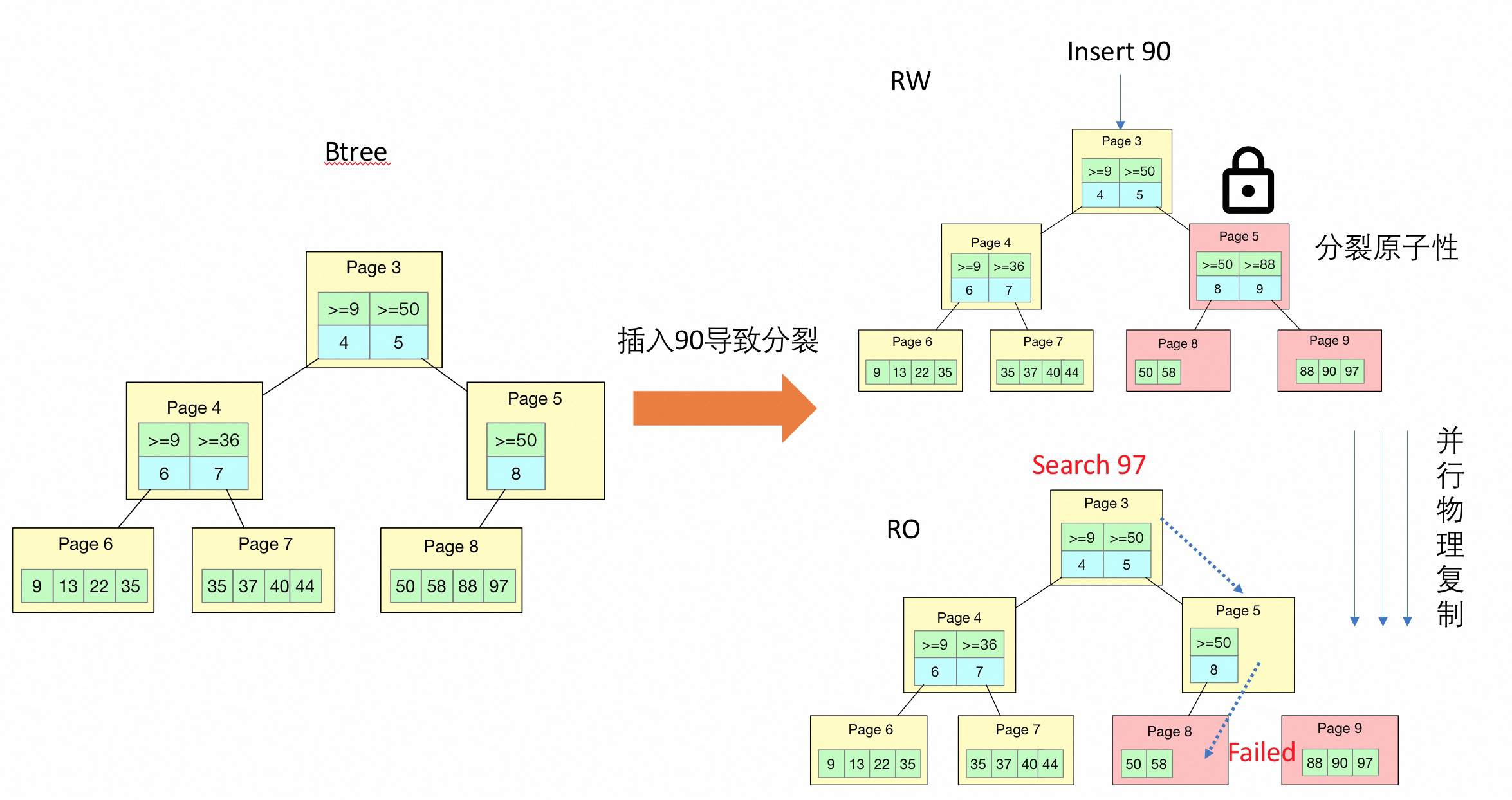
比如在这个场景里面 RO 的Search 97 已经到了Page 5, 这个时候获得child page 是 Page 8, 由于物理复制插入了 90, 因此造成了 Page 8, Page 8 里面的 97 分裂到了 Page 9 中, 所以到 Page 8 Search 97 是Search 不到的.
如果这个Search 97 操作都在 RW 上面进行, 会有这个问题么?
不会有问题的, 因为RW 上面 5.6 之前有x lock 保护, Search 操作需要持有index s lock 与 x lock 是互相冲突的, 所以会等分裂操作结束了在进行. 5.7/8.0 有了sx lock 以后, Search 操作的s lock 和 sx lock 是不冲突的, 但是5.7/8.0 会将对应的子树锁住, 也就是分裂的过程Page 5/8/9 page 是持有x lock 的, 那么 Search 97 操作无法持有 Page 5 s lock, 那么也就不会有问题.
blink-tree 在这个场景里面类似, Search 到 Page 8 的时候, 如果smo 正在进行, 那么需要等待 Page 8 的address lock 上, 等 SMO 结束以后唤醒Search 操作, 重新 search, 确保能够找到对应97 在 Page 9 上面了.
现有解决方法 sync counter
更早之前 index lock
原先的index lock 机制是在应用一批redo log 的时候, 如果该index 发生了smo, 那么就需要持有index x lock, 等这批redo log 应用完成然后释放index x lock.
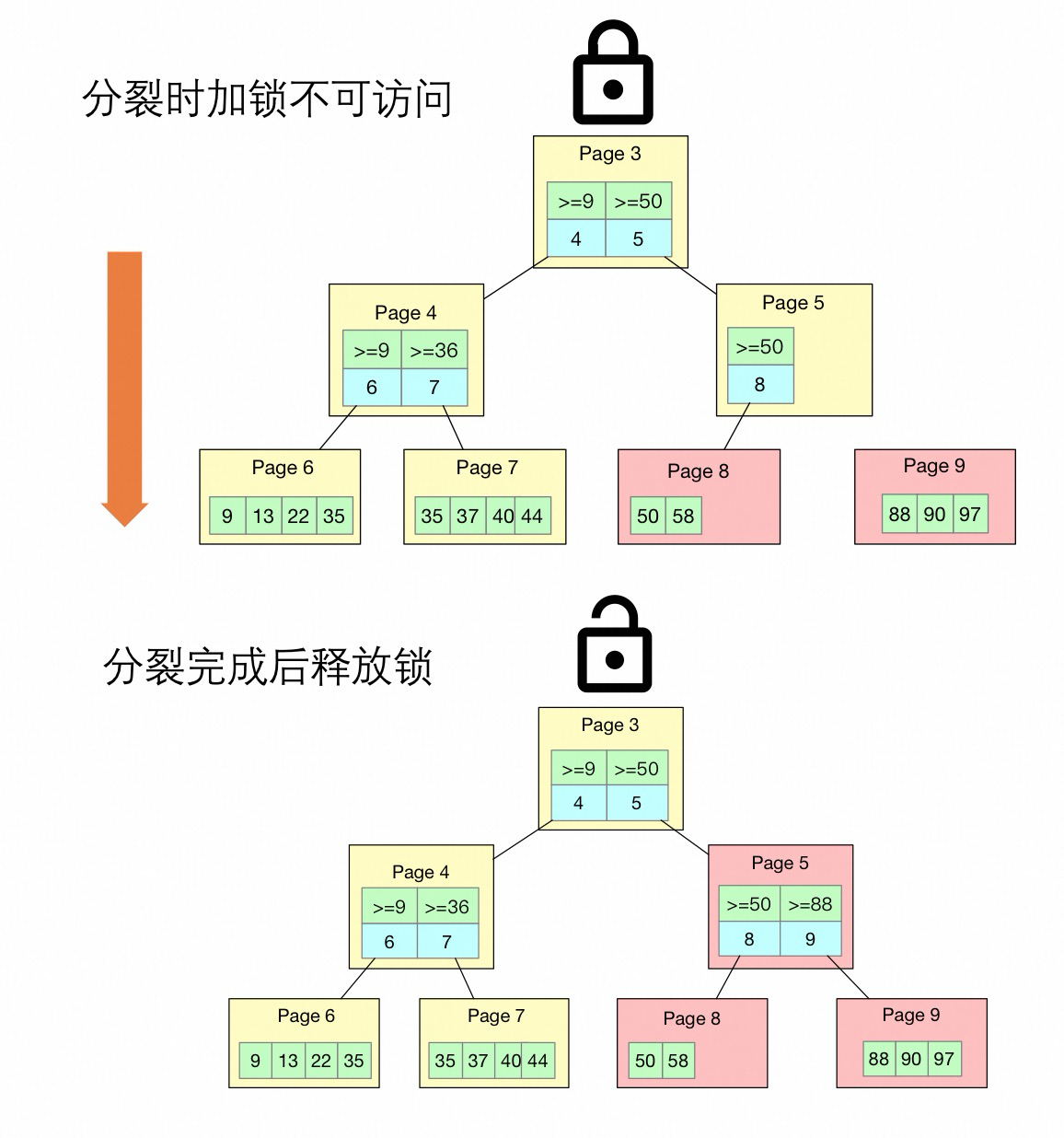
通过添加index x lock, 保证ro 访问到的要么是分裂之前的 Btree 结构, 要么是分裂之后的 Btree 结构.
如何保证?
因为Search 操作需要持有 Index s lock, 如果想要 SMO 完成, 那么就必须等待现有 Search 都结束, 而新的 Search 需等待 SMO 操作都完成才可以进行. 从而保证访问到 Btree 完整性.
上图 Search 操作是 SMO 完成之后的访问.
可以看到这个和最早的 5.6 在 RW 节点上处理 SMO 和 search 操作的方法是一样的, 因为需要持有index x lock, 持有的时间为物理复制apply batch 的时间. 既影响了物理复制的性能, 也影响了用户的请求.
sync counter 机制:
对比原先持有Index lock 持有的时间需要整个apply batch 完成, 新的机制只需要持有更新m_sync_counter 的时间, 但是依然需要持有index x lock.
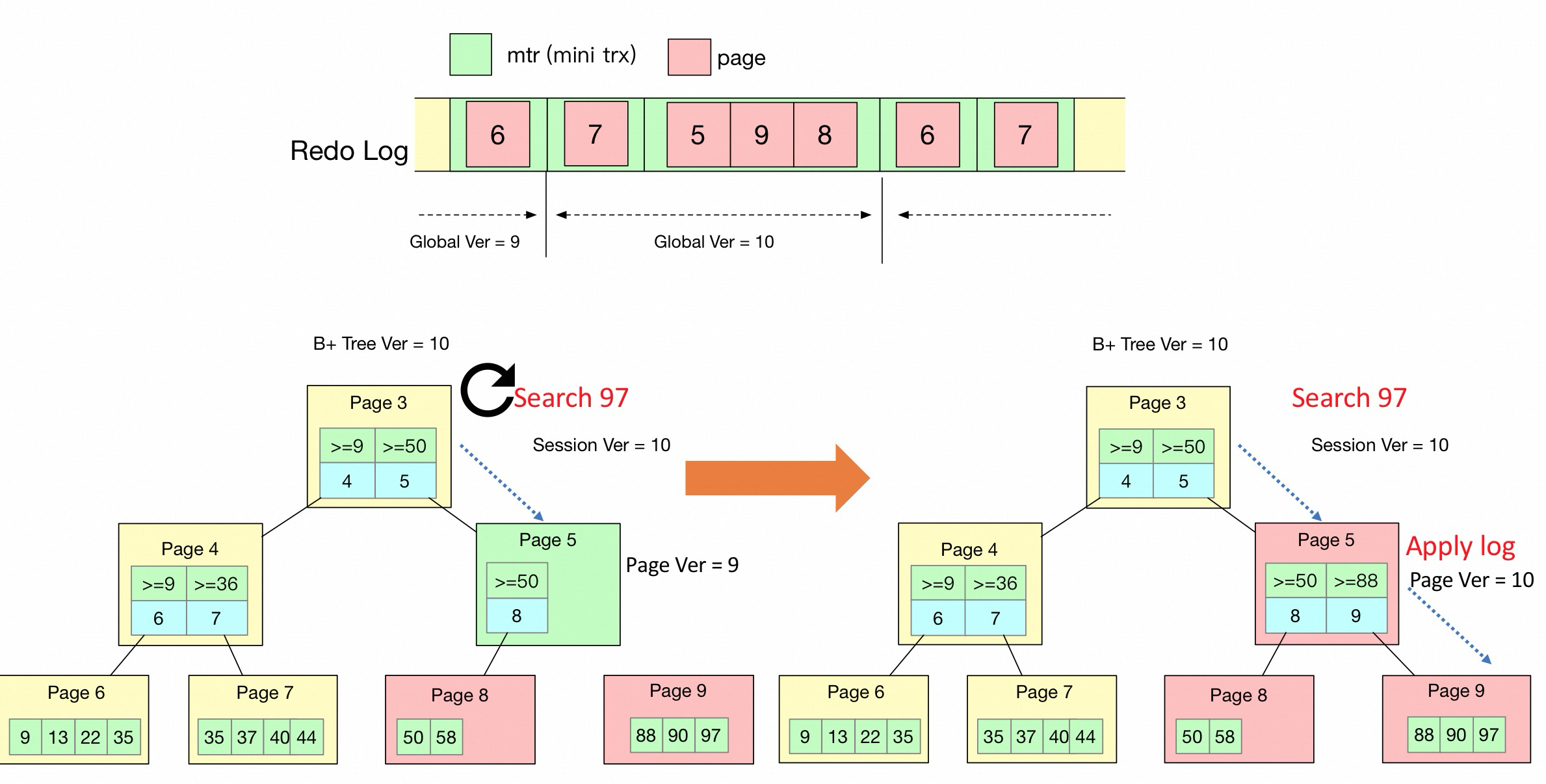
存在的问题:
sync counter 机制在更新index sync_counter 的时候还是需要持有page index lock.
在函数 IndexLockRepl::index_sync_all() => index_sync_with_id() 里面
/* Update the sync counter under protection of index lock. */ rw_lock_x_lock(rw_lock); index->sync_counter = m_sync_counter;
-
正常的search 操作是需要持有index s lock, 更新sync counter 需要持有x lock, 那么就需要等search 操作结束, 因此如果ro 上面读取的操作比较多, 那么apply phase 其实是需要等待的. 也就是影响到了物理复制的效率. (解释一下这里所有的等待都是 mtr 为维度的等待, 不是 trx 维度的等待, 因为 mtr commit 以后, 这个index lock 就会释放了)
-
另外一方面, 由于 sync counter 在更新的过程中是需要持有 index x lock, 而这个 apply phase 由于需要等待其他的 mtr 结束, 造成等待 index x lock 时间过长, 那么同样也会造成新的 search 操作等待时间过长的问题.
相当于 sync counter 把所有的 mtr 操作截成了多个串行的截断.
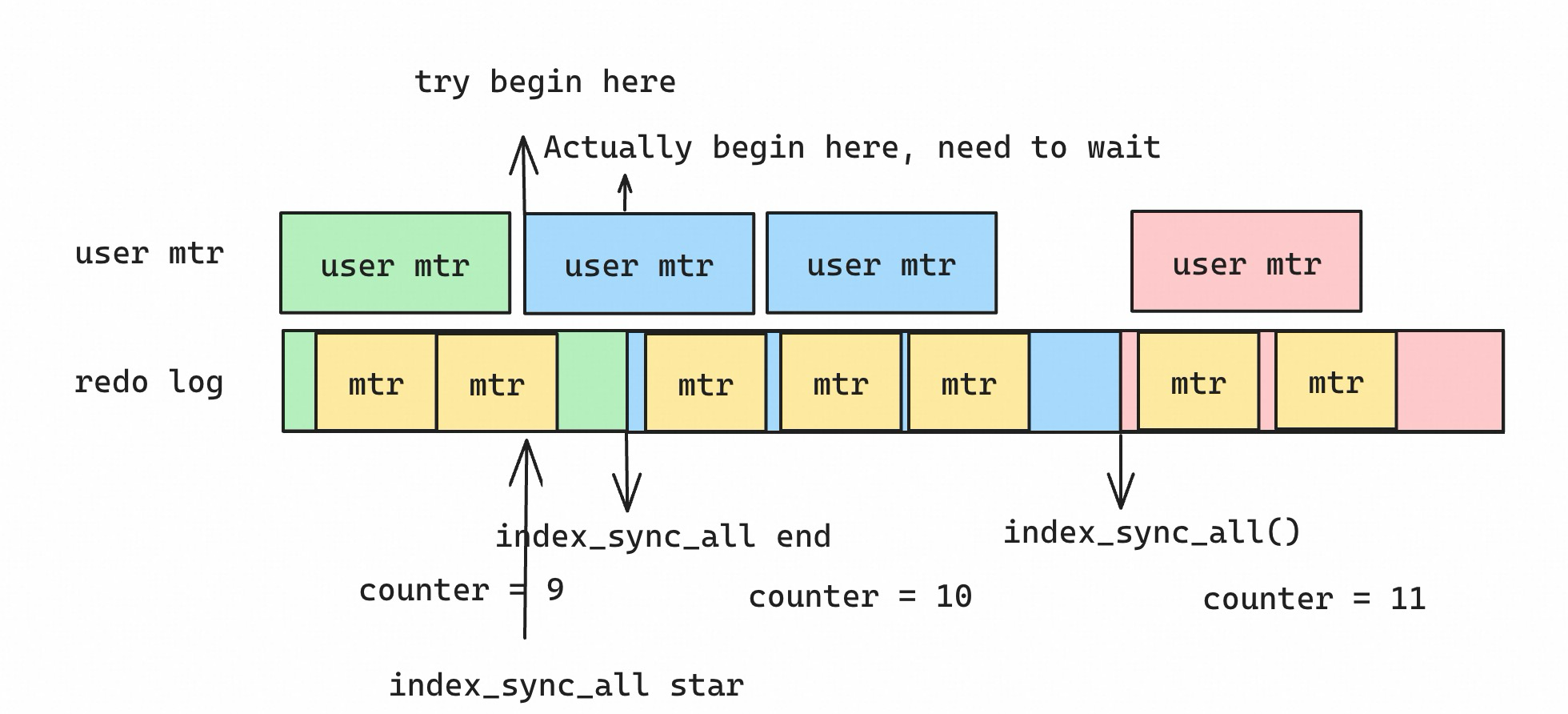
- 还有一个问题, 通过乐观的机制可能导致 search 操作访问next page 的时候, 需要频繁 store_position && restore position 操作, 会频繁的重新遍历btree. 访问child page 的时候, 需要通过apply_runtime_redo 把对应child page apply 到最新版本, 特别是如果 smo 影响的page 与访问的page 无关, 这样的操作更是多余的.
所以sync_counter 对比 5.7/8.0 sx lock 机制已经是更大的加锁范围, 对比blink-tree 更是. 至少sx lock 机制引入可以保证smo 和 search 的冲突仅仅局限在冲突的子树上.
而现有的sync_counter 虽然是乐观的, 但是还是一个smo 影响整个btree 的search, 并且在 RW 有大量的 SMO 场景, 可能导致频繁的store_position && restore_position 从而影响性能.
有更好的方法么?
有的, smo page queue 或者 LogIndex
SMO page queue
目前已经知道有 SMO 操作, 如果可以把发生 SMO page 的 ID 传到RO 节点, 放在一个SMO_array里面, 那么在访问child_page 的apply runtime redo 里面以及next page 的store && restore 操作里面就可以加一个过滤条件, 如果不在SMO_array 里面, 就可以跳过上述的操作, 就不会影响性能了.
上述方法减少了频繁的store && restore 操作, 但是依然存在的一个问题是需要通过index_sync_all 持有 index x lock. 也就是长时间的mtr 会影响物理复制效率, 并且SMO 还是和search 操作冲突.
其实完成可以和主节点一样, SMO 和search 操作不冲突.
完全把 index_sync_all 去掉, 只需要判断是否在SMO_array 里面就可以, 这样实现类似 RW 节点的效果. 也就是Search 操作只和发生 SMO 的 page 之间互相冲突, 其他page 完全不冲突.
并且如果把index_sync_all 操作都去掉, 那么可以实现 SMO 和 SMO 之间也完全不冲突. 也就是类似blink-tree 的效果了.
SMO page queue 解决了SMO 和 Search 冲突的问题, 确保SMO 只会影响 SMO 相应的page. 但是没有解决一个问题, RO 的查询有时候需要访问到过于新的Page, 不过这个问题好像 RW 也存在.
LogIndex
另外一种通过 LogIndex 也可以实现的方法, 就是访问 Page 的时候带上需要lsn 信息, 从而访问到指定版本 Page, 不会出现访问到不存在Page 的情况.
其实 RW 上面也可以通过类似的方法, 这个其实就类似bw-tree 了.
这样其实也解决了非 SMO 场景下面, search 操作page 和正常物理复制apply page 之间的page 冲突.
看过去 LogIndex && bw-tree 非常类似, 有区别么?
bw-tree 和 LogIndex 区别在于bw-tree 在内存中保存的page 是最老版本的page, 加上每一个 page 的 delta-chain, 从而可以读取到任意版本的 page
LogIndex 目前是内存中保留最新版本的 page, 磁盘中保留最老版本 Page, 如果需要读取指定版本 Page, 那么需要通过读取磁盘 Page + parsed redo log 从而访问到任意版本 Page
看过去也有 Socrate 的getPage(lsn) 协议类似, 有区别么?
Socrate getPage(lsn) 协议返回 >= lsn 的任意一个 page
如果 LogIndex && bw-tree 协议返回 <= lsn 的最大lsn_id page.
为什么 Aurora 或者 Socrate 有没有这个问题?
其实也有同样的问题.
Aurora/Socrate 使用的是类似 getPage(lsn) 协议, 返回>= lsn 的任意 page, 那么也会存在访问到的Page 太新, 导致不一致的情况.
具体看 Socrates
注意: Socrates getPage 协议这里返回的 Page 是>= LSN 的任意 Page, 只需要大于 LSN, 不是>= LSN 的第一个 Page, 所以可能存在当前 Page 过于新, 是未来页的情况.
有一个问题?
为什么 getPage(lsn) 协议里面不返回<= LSN 的最大 Page, 这样看过去更合理, 也就不会出现未来页的情况, 而且也不需要通过undo log 去读取历史版本.
Socrates 里面访问到 Future Page 处理的方法非常简单, 就是一个简单的重试, 我们是否也可以?
有没有可能bw-tree 是最适合这种一写多读场景的btree?
TODO:
- ro smo page queue
- 允许读取future page
具体sync_counter 机制代码:
本质原因是因为我们apply redo log 的时候, 是并行apply 的, 一个mtr 里面多个page 是并发修改的, 这个时候如果replica 有读取进来的话, 由于这个mtr 所有pages apply 不是原子的, 所以有可能读取到这个mtr page apply 的中间状态, 就有可能产生读取到的page 的next_page 不对这样的情况.
当然这里btree 访问的3个方向都有可能有问题, 因此都需要处理
-
child page
- next page
-
prev page
-
child page 访问到page 在buf_page_get_gen() 里面通过apply_runtime_redo() 判断是否要应用到最新的redo log 去处理
-
next page 是在 btr_pcur_move_to_next_page() 函数里面, 访问next page 的时候, 因为当前page 里面记录的next page 可能是错误的, 可能next page 已经发生修改了, 因此需要 store_position, restore_position 重新定位当前的page, 确保里面记录的next page 是正确的.
- prev page 由于默认访问prev page 的时候都需要store_position, restore_position. 所以不需要处理.
代码里面可以看到 child page 和 next page 是否可能产生了smo 其实判断条件是一样的.
bool poss_restore = (log_sched->apply_phase_flag.is_set() && (log_sched->index_lock_handler()->sync_counter() == index->sync_counter) && (log_sched->next_apply_lsn() != page_applied_lsn));
都是类似这样的, 下面会解释为什么是这样的判断条件
为什么要区分apply_phase 和 parse_phase?
物理复制parse phase 和 apply phase 是严格分开的, 在parse_phase 的时候是不进行redo apply 的. 因为和用户请求冲突的时候只有在apply phase 的时候, 而parse phase 是不冲突的, 所以在apply phase 阶段的时候, 因为smo 的原因, 需要判断是否执行runtime_apply_redo(), 这个是有开销的.
可以认为区分apply_pahse 和 parse_phase 也是由于page smo 操作引入的, 做的优化
那么好处是在parse 阶段的时候, 我们可以理解之前parse 的redo log 一定已经都apply 完成了, 也就是parse 阶段所有的page 都已经到了 m_applied_lsn
在开启了apply phase 阶段以后, 这一个结论就不成立了.
开启apply phase 以后会设置 m_next_apply_lsn = 上一次parse 完成的lsn.
此刻m_next_apply_lsn > m_applied_lsn.
等这一batch redo log 都apply 完成以后 会把m_applied_lsn 设置成 m_next_apply_lsn. 完成一波redo log 的apply.
那么这个apply phase 期间, 用户请求的读取和page 的更新是同时进行的.
但是在parse phase 期间, 其实所有的page 版本都是一致的, 因为都已经apply 到了同一个版本m_applied_lsn 上了. 并没有后台apply phase 在进行.
所以可以看到处理和用户请求的读取的冲突都在apply phase.
所以现在的smo 策略, 如果和用户读取请求冲突, 那么默认需要对齐到同一个版本, 这个版本就是这一次apply 这一batch redo 的m_next_apply_lsn. 从而保证访问的page 是同一个版本.
当然缺点是该index 上的所有访问, 无论是否冲突, 都需要对齐到最新版本.
产生 MLOG_INDEX_LOCK_ACQUIRE 位置:
增加了MLOG_INDEX_LOCK_ACQUIRE 类型的mtr, 在primary 产生mtr 的时候, 如果这次改动1 个mtr 里面涉及了多个page 的修改, 那么就产生这样的mtr, 具体代码 mtr/mtr0mtr.cc
/* Append the index lock to local buffer */
if (m_impl.m_modifications && m_impl.m_n_log_recs > 0
&& m_impl.m_log_mode != MTR_LOG_NO_REDO
&& m_impl.m_log_mode != MTR_LOG_NONE) {
log_sched->index_lock_handler()->append_log(this);
}
但是这里有个问题, m_impl.m_n_log_recs > 0 能够表示这次mtr 修改了多个page 么?
目前绝大部分mtr 只会修改一个page, 如果一个mtr 修改了多个page, 那么这次修改操作大概率是 SMO 操作.
child page 路径
在btr_cur_search_to_nth_level() => buf_page_get_gen() => apply_runtime_redo 函数里面.
这里其实很多条件是不需要apply_runtime_redo 到最新的
- 如果当前不是 apply_phase
- 如果当前page page.applied_lsn >= next_apply_lsn()
- 如果当前page 在parse buffer 里面并没有需要应用的 redo
- 如果当前index 并没有涉及 SMO 操作, 那么也不需要. 如何知道当前 index 没有涉及 SMO 操作呢? 如下代码
ulint sync_cnt = mtr->get_index_sync_counter();
if (!access_undo && (sync_cnt > 0 && (sync_cnt != index_lock_handler()->sync_counter() || sync_cnt <= index_lock_handler()->prev_sync_counter.load()))) {
return;
}
这里有3个sync_counter.
mtr->sync_cnt: mtr 开始时候的sync_counter, 是从index->sync_counter 拷贝过来. 对应变量: mtr->get_index_sync_counter();
index->sync_counter: 每一次当index 涉及了smo 操作了以后, 对应的 index->sync_counter = global_sync_counter. 对应变量: index->sync_index_sync_counter, 这个值是从index->sync_counter 拷贝了 sync_counter
| sync_cnt != index_lock_handler()->sync_counter() | sync_cnt <= index_lock_handler()->prev_sync_counter.load() |
为什么是这样的判断?
在apply_hashes 函数里面会执行()
-
index_lock_handler()->inc_sync_counter();
-
apply_phase_flag.set();
-
index_lock_handler()->index_sync_all();
line1 将全局的global_sync_counter + 1, 也就是m_sync_counter++;
line2 标记apply_pahse_flags, 为什么需要标记apply_phase_flag 看 physical copy.md
line3 把这一batch 里面涉及smo 的index 都进è_sync_counter);
具体哪些index 做标记是ro 收到MLOG否则都不需要的.
为什么 mtr-> sync_cnt < global_sc 就不需要apply_runtime_redo 了.
因为每次apply_phase 的时候 global_sc 都会+1, 当 mtr->sync_cnt < global_sc 的时候, 说明当前mtr 开始的时候是apply 之前的batch.
那么如果mtr 开始的batch1 和当前batch2 之间有smo 发生了, 也不会有问题么?
比如mtr 开始的时å 虽然mtr 运行的过程中持有page 8 s lock, 但是并¡有持有page 9, page 10 的x lock, 那么此时后台的appl¯发生了smo 操作, global_sc = 101, 那么会有问题么? arch_to_nth_level() 执行过程是持有index->lock s lock, 那么此时这个apply_pahse 是会被堵住的, 因为只有等到btree 遍历完, btr_cur_search_to_nth_level() 执行完才会将index->lock s lock 给释放, 这两个操作互斥, 因此就不会出现遍历btree 一半的过程中, 后台的apply phase 把某一些page 给修改了, 而是一定等所有的btree 遍历完, 再开始apply phase.
所以只要syno()到最新.
另外一个问题:
如果RO 节点出现 mtr 一直没有结束, 后台物理复制的redo batch apply 如何处理?
不会的, 分两种场景
- 如果当前inde¸直没有smo, 那么物理复制会一直正常进行的, 潓前mtr->sync_count 依然是100 也是不会有问题, 如果undo log 找到指定的版本.
- 如果当前index 出现了本的son node B
这样就造成了遍历一个btree 访问到不同版本的page 了.
现在好像不会出现这个问题了, 因为apply thread 需要拿到index lock 之后才可ä`c++ bool poss_restore = (log_sched->apply_phase_flag.is_setapply_lsn() != page_applied_lsn));
和上面判断apply_r因为log_sched->next_apply_lsn 是当前这一批batch redo 都apply 完以后的lsn.
因此不相等的话, 说明是老的页.
如果相等的话, 说明这个page 已经更新到这一批batch redo apply 了, 已经是最新版本了, 那就不用restore 了.
另外, 这里在restore_position 的时候是需要持有index s lock, 为什么呢?
```c++
mtr_s_lock(dict_index_get_lock(index), mtr);
btr_pcur_restore_position(BTR_SEARCH_LEAF | BTR_ALREADY_S_LATCHED,cursor, mtr);
持有index s lock 其实就和apply phase 互斥, 为了实现访问child page btr_cur_search_to_nth_level() 持有index s lock 一样的逻辑. 这样后台的apply phase 就无法进行, 因此apply phase 更新index->sync_counter 需要持有index x lock.
prev page 路径
访问prev_page 路径由于天然需要store_position 和 restore_position 所以不需要改动.