InnoDB B-tree Latch Optimization History
In general, in a database, “latch” refers to a physical lock, while “lock” refers to a logical lock in transactions. In this article, the terms are used interchangeably.
In the InnoDB implementation, there are two main types of locks in the B-tree: index lock and page lock.
- Index lock refers to the lock on the entire index, which is represented in the code as
dict_index->lock. - Page lock refers to the lock present on each page within the B-tree.
When we refer to B-tree locks, we generally mean both the index lock and the page lock working together.
In the 5.6 implementation, the process of B-tree latching is relatively simple, as follows:
1. For a query request:
- First, acquire an S LOCK on
btree index->lock. -
Then, after finding the leaf node, acquire an S LOCK on the leaf node as well, and release the
index->lock.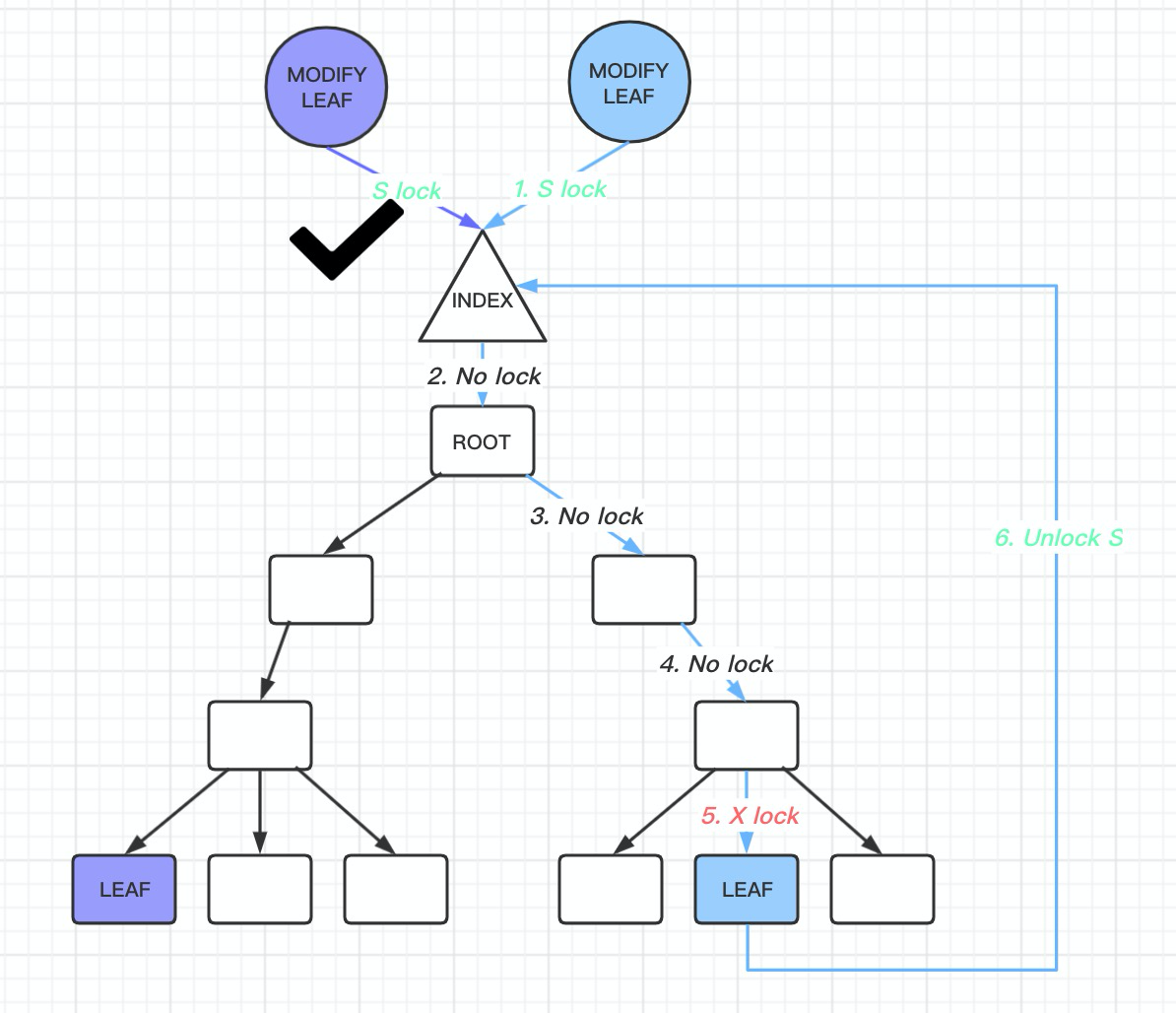
2. For a leaf page modification request:
- Similarly, acquire an S LOCK on
btree index->lock. - Then, after finding the leaf node, acquire an X LOCK on it because the page needs to be modified. After that, release the
index->lock. At this point, there are two scenarios depending on whether the modification of this page will cause a change in the B-tree structure:- If it doesn’t, that’s good. Once the X LOCK on the leaf node is acquired, modify the data and return.
-
If it does, you will need to perform a pessimistic insert operation and re-traverse the B-tree. Acquire an X LOCK on the B-tree index and execute
btr_cur_search_to_nth_levelto the specified page.Since modifying the leaf node may cause changes to the B-tree all the way up to the root node, other threads must be prevented from accessing the B-tree during this time. Therefore, an X LOCK is required on the entire B-tree, meaning no other query requests can access it. Moreover, since an X LOCK is held on the index, and record insertion into the page might cause the upper-level pages to change, this process may involve disk I/O, potentially making the X LOCK last for an extended time. During this time, all read-related operations will be blocked.
The specific code for this is in
row_ins_clust_index_entry. Initially, an optimistic insert operation is attempted:err = row_ins_clust_index_entry_low( 0, BTR_MODIFY_LEAF, index, n_uniq, entry, n_ext, thr, &page_no, &modify_clock);If the insert fails, a pessimistic insert operation is attempted:
return(row_ins_clust_index_entry_low( 0, BTR_MODIFY_TREE, index, n_uniq, entry, n_ext, thr, &page_no, &modify_clock));As you can see, the only difference here is that the
latch_modeis eitherBTR_MODIFY_LEAForBTR_MODIFY_TREE. Sincebtr_cur_search_to_nth_levelis executed in therow_ins_clust_index_entry_lowfunction, the B-tree is re-traversed when the pessimistic insert is retried after a failed optimistic attempt.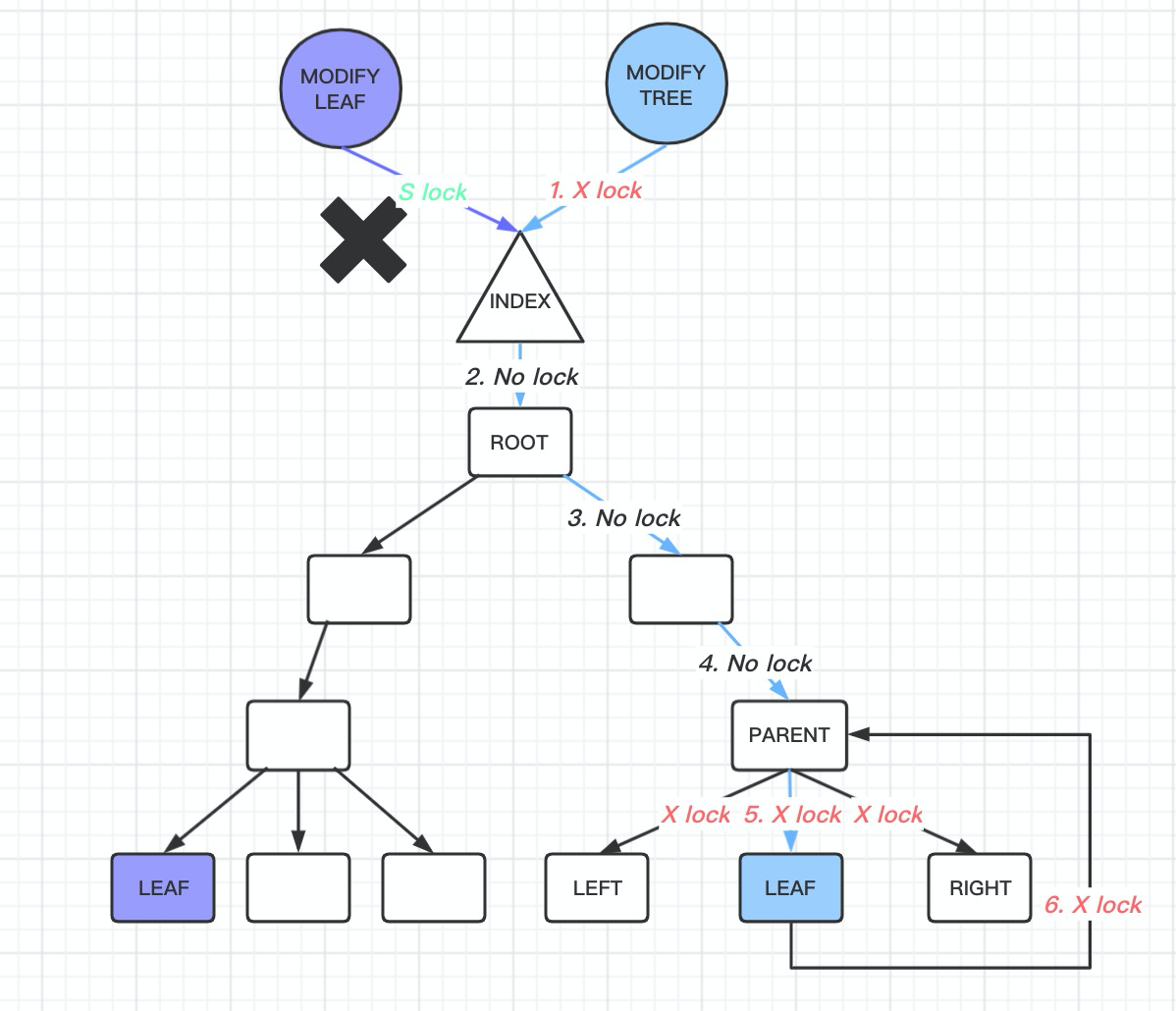
As shown above, in 5.6, the index lock is only applied to the entire B-tree index, and the page lock is applied only to leaf node pages in the B-tree. Non-leaf node pages in the B-tree are not locked.
This simple implementation makes the code easy to understand, but it has obvious disadvantages. During SMO (Structure Modification Operation), read operations cannot proceed, and because SMOs may involve disk I/O, the resulting performance fluctuations are quite noticeable. We have often observed such phenomena in production.
The 8.0 Improvements
In response, official changes were introduced, starting in 5.7. Here, we’ll take 8.0 as an example. The main improvements include:
- The introduction of SX LOCK.
- The introduction of non-leaf page locks.
SX LOCK Introduction
Let’s first introduce SX LOCK. SX LOCK can be used for both index locks and page locks.
- SX LOCK does not conflict with S LOCK but does conflict with X LOCK. SX LOCKs also conflict with each other.
- The purpose of an SX LOCK is to indicate the intention to modify the protected area, but the modification has not yet started. Therefore, the resource is still accessible, but once the modification begins, access will no longer be allowed. Since an intention to modify exists, no other modifications can occur, so it conflicts with X LOCKs.
The main usage now is that index SX LOCK does not conflict with S LOCK, which allows reads and optimistic writes to proceed even during pessimistic insert operations.
SX LOCK was introduced through this work log: WL#6363.
SX LOCK was primarily introduced to optimize read operations. Since SX LOCK conflicts with X LOCK but not with S LOCK, places that previously required X LOCKs were changed to SX LOCKs, making the system more read-friendly.
Non-leaf Page Lock Introduction
In fact, this is how most commercial databases operate—both leaf pages and non-leaf pages have page locks.
The main idea is Latch Coupling, where during a top-down traversal of the B-tree, the page lock on the parent node is released only after acquiring the lock on the child node. This minimizes the lock coverage. To implement this, non-leaf pages must also have page locks.
However, InnoDB did not completely remove the index->lock, which means that only one BTR_MODIFY_TREE operation can occur at a time. Therefore, when B-tree structure modifications are highly concurrent, performance can degrade significantly.
Back to the 5.6 Problem
As we can see, in 5.6, the worst-case scenario is when modifying a B-tree leaf page triggers a change in the B-tree structure. In this case, an X LOCK on the entire index is required. However, we know that such changes may only affect the current page and the page at the next level. If we can reduce the lock scope, it will undoubtedly help improve concurrency.
In MySQL 8.0
1. For a query request:
- First, acquire an S LOCK on
btree index->lock. - Then, during the B-tree traversal, acquire an S LOCK on the non-leaf node pages encountered.
-
After reaching the leaf node, acquire an S LOCK on the leaf node page and release the
index->lock.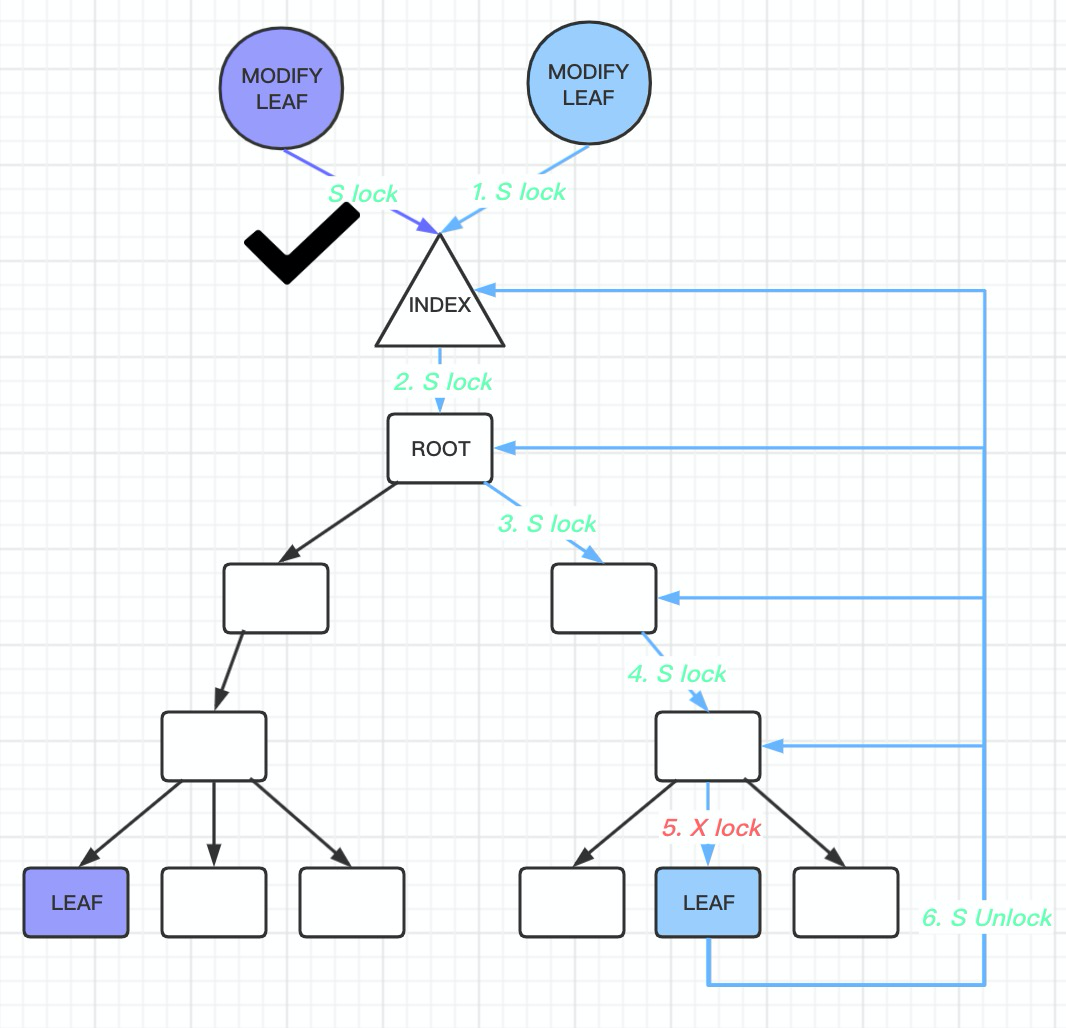
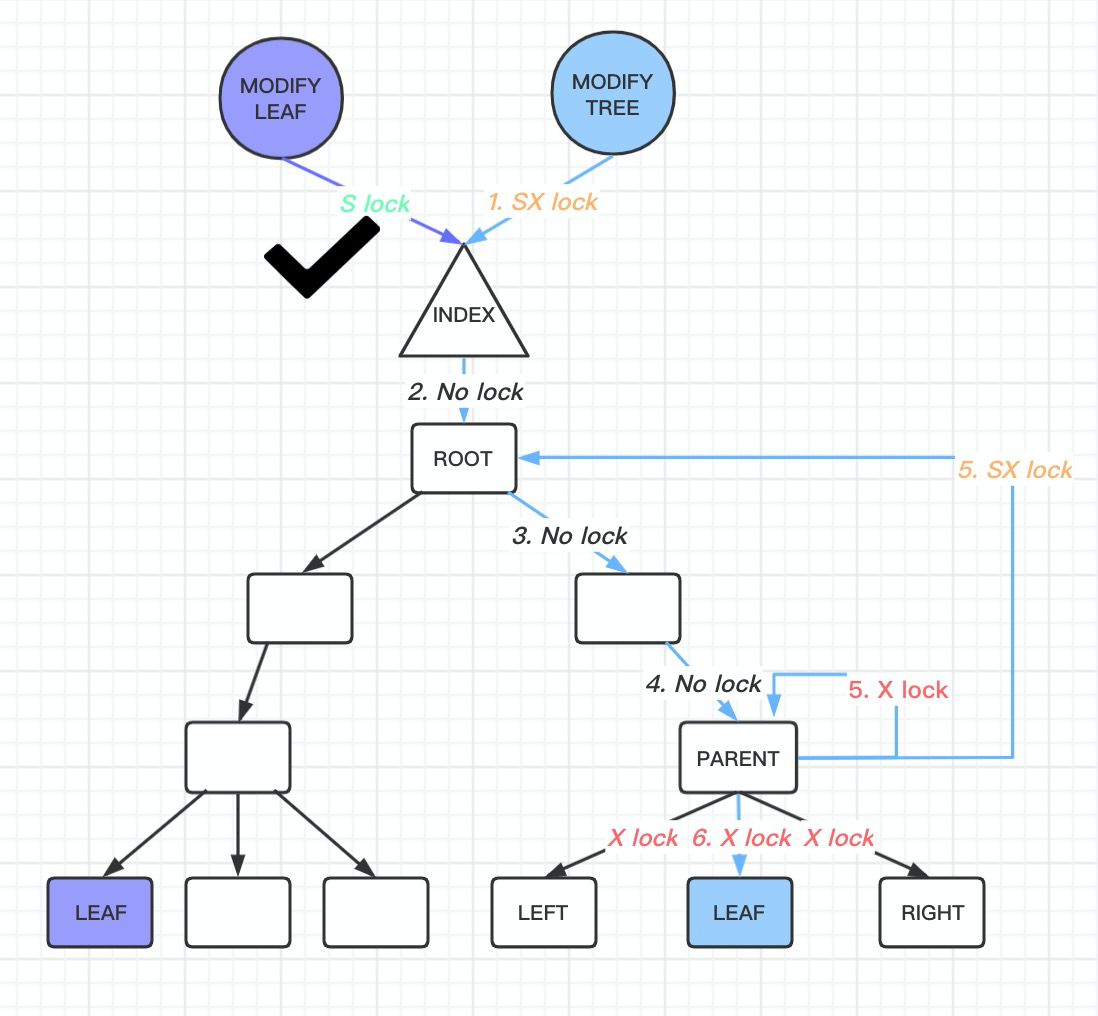
2. For a leaf page modification request:
- Similarly, acquire an S LOCK on
btree index->lockand S LOCKs on the non-leaf node pages. - After reaching the leaf node, acquire an X LOCK on the leaf node because the page needs to be modified, and then release the
index->lock. At this point, the situation branches into two scenarios depending on whether the page modification triggers a B-tree structure change:- If it doesn’t, then the X LOCK on the leaf node is sufficient. After modifying the data, return as normal.
- If it does, a pessimistic insert operation is performed by re-traversing the B-tree. At this point, the
index->lockis acquired with an SX LOCK.- Since the B-tree now has an SX LOCK, the pages along the search path do not require locks. However, the pages encountered during the search process need to be saved, and X LOCKs are applied to the pages that may undergo structural changes.
- This ensures that read operations are minimally affected during the search process.
- Only after confirming the scope of the B-tree changes at the final stage, and acquiring X LOCKs on the affected pages, will the operation proceed.
In 8.0, the duration of holding the SX LOCK is as follows:
-
Holding the SX LOCK: After the first
btr_cur_optimistic_insertfails,row_ins_clust_index_entrycallsrow_ins_clust_index_entry_low(flags, BTR_MODIFY_TREE ...)to insert. Insiderow_ins_clust_index_entry_low, the SX LOCK is acquired in thebtr_cur_search_to_nth_levelfunction. At this point, the B-tree is locked by the SX LOCK, preventing further SMO operations. An optimistic insert is still attempted at this stage, with the SX LOCK still being held. If that fails, a pessimistic insert is attempted. -
Releasing the SX LOCK: In a pessimistic insert, the SX LOCK is held until a new page (page2) is created and connected to the parent node. If the page undergoing SMO is a leaf page, the SX LOCK is released only after the SMO operation is completed, and the insert is successful.
The function responsible for executing the SMO and inserting is btr_page_split_and_insert.
The btr_page_split_and_insert operation consists of approximately 8 steps:
1. Find the record to split from the page that is about to be split. Ensure the split location is at the record boundary.
2. Allocate a new index page.
3. Calculate the boundary record for both the original page and the new page.
4. Add a new index entry for the new page to the parent index page. If the parent page does not have enough space, it triggers the split of the parent page.
5. Connect the current index page, the current page’s prev_page, next_page, father_page, and the newly created page. The connection order is to first connect the parent page, then prev_page/next_page, and finally connect the current page and the new page. (At this point, the index->sx lock can be released.)
6. Move some records from the current index page to the new index page.
7. The SMO operation is complete, and the insertion location for the current insert operation is calculated.
8. Perform the insert operation. If the insert fails, try reorganization of the page and attempt the insert again.
In the existing code, there is only one scenario where index->lock will acquire an X lock, which is:
if (lock_intention == BTR_INTENTION_DELETE && trx_sys->rseg_history_len > BTR_CUR_FINE_HISTORY_LENGTH && buf_get_n_pending_read_ios()) {
// If the lock_intention is BTR_INTENTION_DELETE and the history list is too long, the index will acquire an X lock.
Summary:
Improvements in 8.0 compared to 5.6
In 5.6, during a write operation, if an SMO (structure modification operation) is in progress, the entire index->lock would be locked with an X lock. During this time, all read operations would be blocked.
In 8.0, read operations and optimistic write operations are allowed to proceed during an SMO.
However, in 8.0 there is still a limitation: only one SMO can occur at a time because the SX lock must be acquired during an SMO. Since SX locks conflict with other SX locks, this remains one of the main issues in 8.0.
Optimization Points:
Of course, there are still some optimization opportunities here.
-
There is still a global
index->lock. Although it is an SX LOCK, in theory, according to the 8.0 implementation, it is possible to fully release the index lock. However, many details need to be handled. -
During the actual split operation, can the holding of the index lock inside
btr_page_split_and_insertbe optimized further?-
For example, based on a certain sequence, could the
index->lockbe released after connecting the newly created page to thenew_page? -
Another consideration is the holding time of the X LOCK on the page where the SMO (structure modification operation) occurs.
Currently, the X LOCK is held on all pages along the path until the SMO is completed, and the current insert operation is finished. Meanwhile, the
father_page,prev_page, andnext_pagealso hold X LOCKs. Could the number of locked pages be reduced? For example, this optimization is mentioned in BUG#99948. -
In
btr_attach_half_pages, multiple traversals of the B-tree usingbtr_cur_search_to_nth_levelcould be avoided. This function is responsible for establishing links like the father link, prev link, and next link. However, it redundantly executesbtr_page_get_father_blockto traverse the B-tree to find the parent node, which internally callsbtr_cur_search_to_nth_level. This step could be avoided since the index is already SX LOCKed, and the father node won’t change. The result from the previousbtr_cur_search_to_nth_levelcall could be reused. -
Can we mark pages undergoing SMO with a state similar to a B-link tree, where the page is still readable? Although the record to be read might not exist on the current page, the reader could attempt to retrieve it from the page’s
next_page. If the record can be found, the read operation is still valid.
-
-
Can the pages encountered during the
btr_cur_search_to_nth_levelsearch be preserved? This way, even for repeated searches, only the maxtrx_idof the upper-level pages needs to be checked. If unchanged, the entire search path hasn’t changed, so no full traversal is necessary. -
Is it still necessary to retain the optimistic insert followed by a pessimistic insert approach?
My understanding is that this process exists because the cost of pessimistic inserts was too high in the 5.6 implementation. To minimize pessimistic inserts, this process was carried over into the current 8.0 implementation. However, multiple insert attempts require multiple B-tree traversals, leading to additional overhead.
talking
https://dom.as/2011/07/03/innodb-index-lock/
https://dev.mysql.com/worklog/task/?id=6326