DuckDB 的 MVCC 设计与 HyPer 模型
简单介绍一下 DuckDB MVCC 参考的 HyPer-style 设计
DuckDB 的 MVCC 实现参考 Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems 实现 本文简单介绍 DuckDB 中这一套 MVCC 机制的设计思路, 以及与 InnoDB, Oracle 等数据库在可见性判断与版本号分配上的不同.
在这个 MVCC 实现里面, 有三个变量:
- transactionID
- startTime-stamps
- commitTime-stamps
事务启动时, 系统会同时分配 transactionID 与 startTime-stamps
-
transactionID 是从 2^63 次方开始增长, 是一个非常大的值
-
startTime-stamps 是从 0 开始递增
-
commitTime-stamps 是在提交的时候才会赋值, 来着与 startTime-stamps 相同的递增计数器.
这个设计与 InnoDB 中的 trx_id / trx_no 关系类似:
transactionID 对应 InnoDB 的trx_id,startTime-stamp 与 commitTime-stamp 对应 trx_no.
区别在于:
DuckDB 在事务运行过程中对于每一个行的修改记录的 UndoBuffer 是 transactionID, 这个 transactionID 是一个非常大的值, 那么对于这个值就只有当前事务能够看到了. 在事务提交的时候, DuckDB 会将 UndoBuffer 中这些版本的时间戳从transactionID 更新为 commitTime-stamps.
在可见性判断的时候的时候, 由于 transactionID 肯定比startTime-stamps 大, 那么自然未提交的事务就不会被其他事务看到, 使得可见性判断非常简单.
Version Access 可见性判断函数
v.pred = null ∨ v.pred.TS = T ∨ v.pred.TS < T.startTime
即对于事务 T:
-
如果某行没有旧版本
-
或该行的版本时间戳等于当前事务的 transactionID
-
或该行版本的时间戳小于当前事务的 startTime-stamps
则该行对事务 T 可见, 否则就不可见
以下面的例子为例.
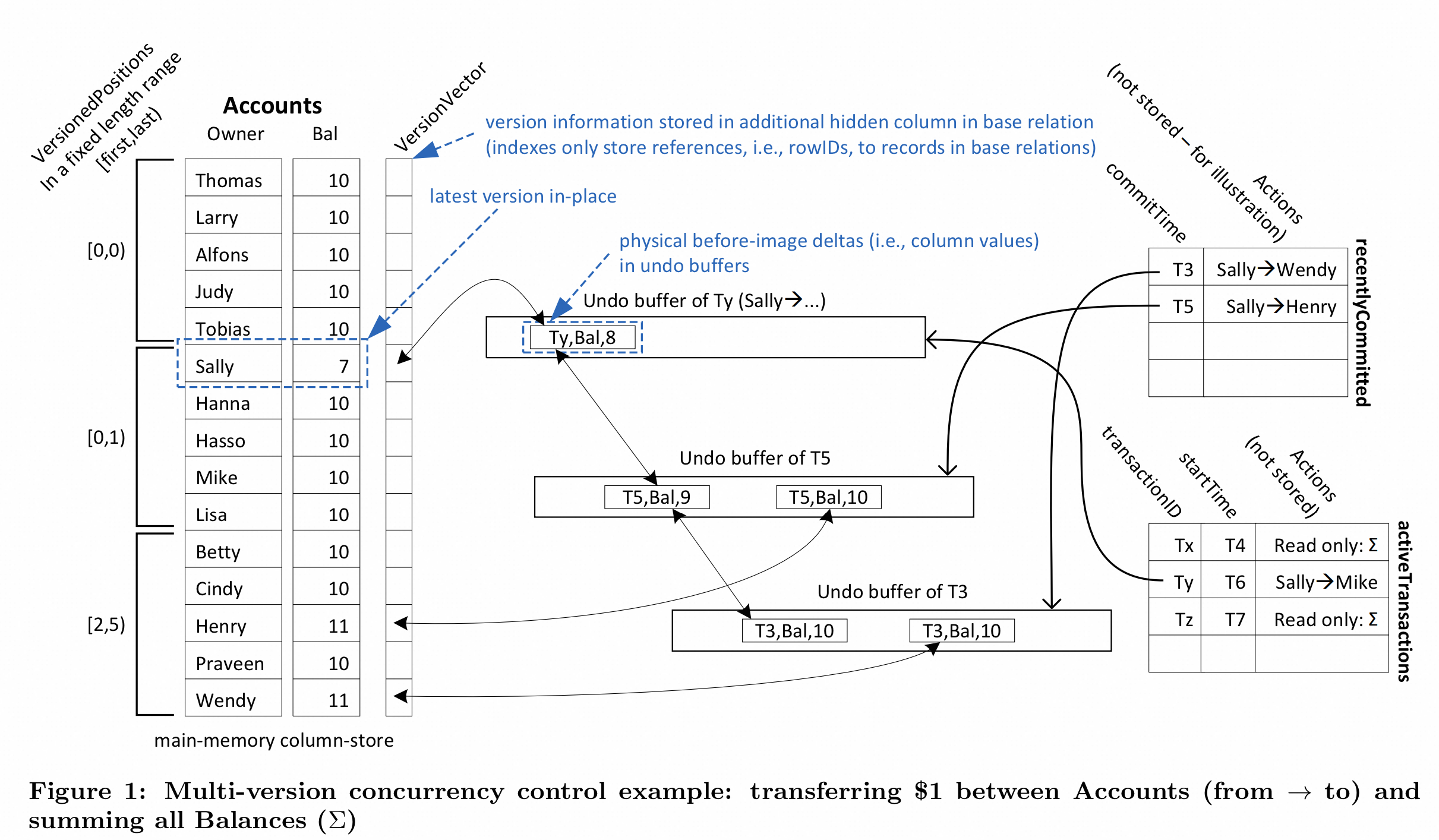
原本所有人的余额 Bal(balance) = 10, 发起了 3 个事务.
| 事务 | 操作 | 说明 |
|---|---|---|
| trx1 | T3 时刻开启, Sally → Wendy 转 1 元 | 已经提交, 在 recentlyCommitted 事务数组 |
| trx2 | T5 时刻开启, Sally → Henry 转 1 元 | 已经提交, 在 recentlyCommtted 事务数组 |
| trx3 | T6 时刻开启, Sally → Mike 转 1 元 | 未提交, 在 activeTransactions 数组 |
| trx4 | T4 时刻开启, 统计所有人的余额 | startTime = T4, transactionID = Tx |
| trx5 | T7 时刻开启, 再次统计余额 | starTtime = T7, transactionID = Tz |
(注意: 这里 Undobuffer timestamp 判断的是前向的 value, 如: undo buffer of Ty 对应的是 7 是否可见, undo buffer of T5 对应的是 8 是否可见)
当trx4 在 T4 时间点进行读取, 由于它的 startTime = T4 > T3, 那么是可以看到 T3 提交的内容, Undo buffer of T3 的前向 value 是 Sally =9, Wendy = 11. 其他事务还未开始, 直接读取最新版本即可.
重点是trx3, 由于 trx3 还未提交, Sally 指向的第一个undo buffer 记录sally -> Mike 这个操作, 但是还在进行中, Mike 还没有执行 Mike + 1 操作. 由于事务还未提交, 这个 undo buffer 时间戳就是 Ty, Ty 是trx3 的transactionID, 是一个非常大的值.
比如事务 trx5, 虽然 startTime = T7, 比 trx3 的startTime T6要来的大, 但是根据下面的可见性判断可以看到, 由于trx5.transactionID != undo buffer of Ty, 并且trx5.startTime < undo buffer of Ty, 那么 undo buffer of Ty 对应的值 7 就是对trx5 是不可见的. 而 Undo buffer of T5 < T7, 那么 Ty, Bal,8 就是 trx5 可见的了.
DuckDB 判断事务可见性的时候, 并没有使用类似InnoDB/PostgreSQL 活跃事务数组, 而是直接通过 start_time 就可以判断了. 类似Oracle SCN 实现方式.
DuckDB 没有类似 InnoDB readview 如何解决可见性判断?
现有的InnoDB 里面trx_id, trx_no 就类似start_ts, end_ts.
对于某一行的可见性本质是判断这一行的内容在当前trx1 开始的时候有没有提交了.
在 InnoDB 里面就是判断当前事务是 trx_id 是否大于读取到的 row 的trx_no.
但是这里的问题是, 在行上面记录的是 trx_id, 而不是 trx_no.
那么为什么在行上面只记录了 trx_id, 而不把 trx_no 也记录下来呢?
因为如果这样做的话, 开销会非常大.
InnoDB 是支持steal and no force, 也就是事务commit 之前可能对应的 record 就已经落盘了, 因此 InnoDB 现在写record 的时候是不知道trx_no 的, 需要在commit() 执行 trx_write_serialisation_history() 获得trx_no 之后, 再重新写一次record 对应的trx_no 到record 才可以实现.
这样的话, commit 的时候如果修改了 1000 行数据, 那么就需要重新对1000 行数据的undo log 重新进行修改, 开销非常大.
因为从行上只读读取到 trx_id, 所以 InnoDB 里面判断事务的可见性并没有使用 trx_no, 而是使用事务开始的事务号 trx_id. 那么通过 trx_id 来进行判断的话, 就需要结合活跃事务数组 readview 来一起进行判断可见性了.
所以其实如果行上面记录的是trx_no, 那么就不需要 readview, 直接拿来比较就可以了.
这里怎么判断呢?
还是一开始的需求, 当前读取到的行是否在 trx1 开始前就已经提交了, 那么通过 readview 可以获得 trx1 开启的时候有哪些事务还在运行中, 如果还在那么肯定说明还未提交. 另外就是比活跃事务数组最大的 trx_id 的事务也一定未提交, 因为事务启动的时候 copy readview 都没有, 说明事务启动的时候对应的事务肯定还未提交.
那么 Oracle 怎么规避这个问题呢? 以及类似的解决方案都如何解决这个问题?
常见的优化思路就是, 写入的时候记录一个 trx_id => trx_no 的映射关系表id_no_map. 减少commit 的时候去给每一个record 写入trx_no 的开销, 记录在id_no_map table 上.
id_no_map 可以是纯内存的, 也可以是持久化的. 纯内存是因为事务重启以后, 老的trx_id 对于新事物都是可见的, 所以如果这个id 小于mysql 启动的时候事务 trx id, 那么该事务肯定是可见的.
如果该id 大于启动的时候事务trx id, 并且在id_no_map table 上找不到, 那么是未 commit 的, 否则就获得对应的trx_no.
那么一个事务trx1.trx_id 就可以与读取到的某一行直接进行判断. 如果 trx1.trx_id > id_no_map[trx_id], 那么该行就对该事务可见, 如果trx1.trx_id < id_no_map[trx_id] 那么改行就是trx1 启动以后才commit 的, 那么就不可见了.
当然这里需要考虑trx_id 不断增长以后, 老的trx_id => trx_no 映射关系就要清理掉, 否则就要占用内存空间了.
Oracle 里面把这个信息放在了每一个 Page 上面的ITL 槽(Interested Transaction List)
关键信息: 每个 ITL 槽通常包含:
- 事务 ID (XID):唯一标识一个事务.
- 提交 SCN (Commit SCN):当事务提交时, 这个槽位会被更新为事务的提交 SCN. 如果事务未提交或回滚, 这个值通常是 NULL或一个特殊值(如 0x0000.00000000).
那么读取都 Page 里面某一个行的时候, 读取到行的 XID 信息以后, 会根据这个 Page 上面的ITL 去把 XID mapping 到 SCN 上去. 因为ITL 是 Page 级别, 而不是 Record 级别, 所以可以将需要 1000 行的 record 的修改改成只需要 1 次 Page 的修改.
DuckDB 在实现上进一步简化, DuckDB 这里有两个优势, 实现起来非常简单.
- DuckDB 的 undo log 都是在内存里面的, 不需要持久化, 所以不存在把 id_no_mapping 持久化的这个需求, 也就不需要有清理等等一系列操作了
- DuckDB 的 undo log 是 chunk(2048行) 级别, 而不是行级别, 也就是修改了 2048 行, 只需要改一个 version number 就可以, 不需要改 2048 个