MySQL InnoDB Buffer pool 并发控制
InnoDB 对buffer pool 的访问除了包含了用户线程会并发访问buffer pool 以外, 同时还有其他的后台线程也在访问buffer pool, 比如刷脏, purge, IO 模块等等, InnoDB 主要通过5个不同维度的mutex, rw_lock, io_fix 进行并发访问的控制
- free/LRU/flush list Mutex
- hash_lock rw_lock (在5.6 之前, 只会有一个大的buffer pool Mutex)
- BPageMutex mutex
- io_fix, buf_fix_count
- BPageLock lock rw_lock
free/LRU/flush list Mutex
所有的page 都在free list, LRU list, flush list 上, 所以大部分操作第一步如果需要操作这几个list, 需要首先获得这几个list mutex, 然后在进行IO 操作的过程, 是会把list Mutex 放开.
但是只有LRU list Mutex 的latch order 在page mutex 前面, 因此持有LRU list Mutex 可以直接持有page mutex, 但是持有free list/flush list 则不可以. (下面会提到 latch order)
InnoDB 也是尽可能让持有LRU list, flush list 的时间尽可能短
hash_lock rw_lock
一个buffer pool instance 下面的buffer block 都存在一个hash table上
这个hash_lock 是这个hash_table 上面的slot/segment 的rw_lock, 也就是这个hash table 有多少个slot, 就有多少个这个hash_lock, 这个hash_lock 的引入也是为了尽可能的减少锁冲突, 这样可以做到需要写入的时候锁的只是这个hash_table 的slot/segment 级别
这里InnoDB 优化这个lock level 从整个hash table 到hash table slot 级别, 在5.6 之前的版本, 是一个整个hash table mutex.
从代码里面可以看到, 总是先拿 hash_lock, 然后才是 buffer block mutex 或者是 page frame mutex
BPageMutex mutex
我们也叫做page block mutex, 在buf_block_t 结构体里面.
BPageMutex mutex 保护的是io_fix, state, buf_fix_count, state 等等变量, 引入这个mutex 是为了减少早期版本直接使用buffer pool->mutex 的开销
可以理解BPageMutex 是保护buf_block_t 结构体, 而下面BPageLock 是为了保护page frame
比如常见代码
ib_mutex_t* mutex = buf_page_get_mutex(&block->page);
mutex_enter(mutex);
io_fix = buf_block_get_io_fix(block);
mutex_exit(mutex);
io_fix, buf_fix_count
io_fix, buf_fix_count 受 page block mutex的保护.
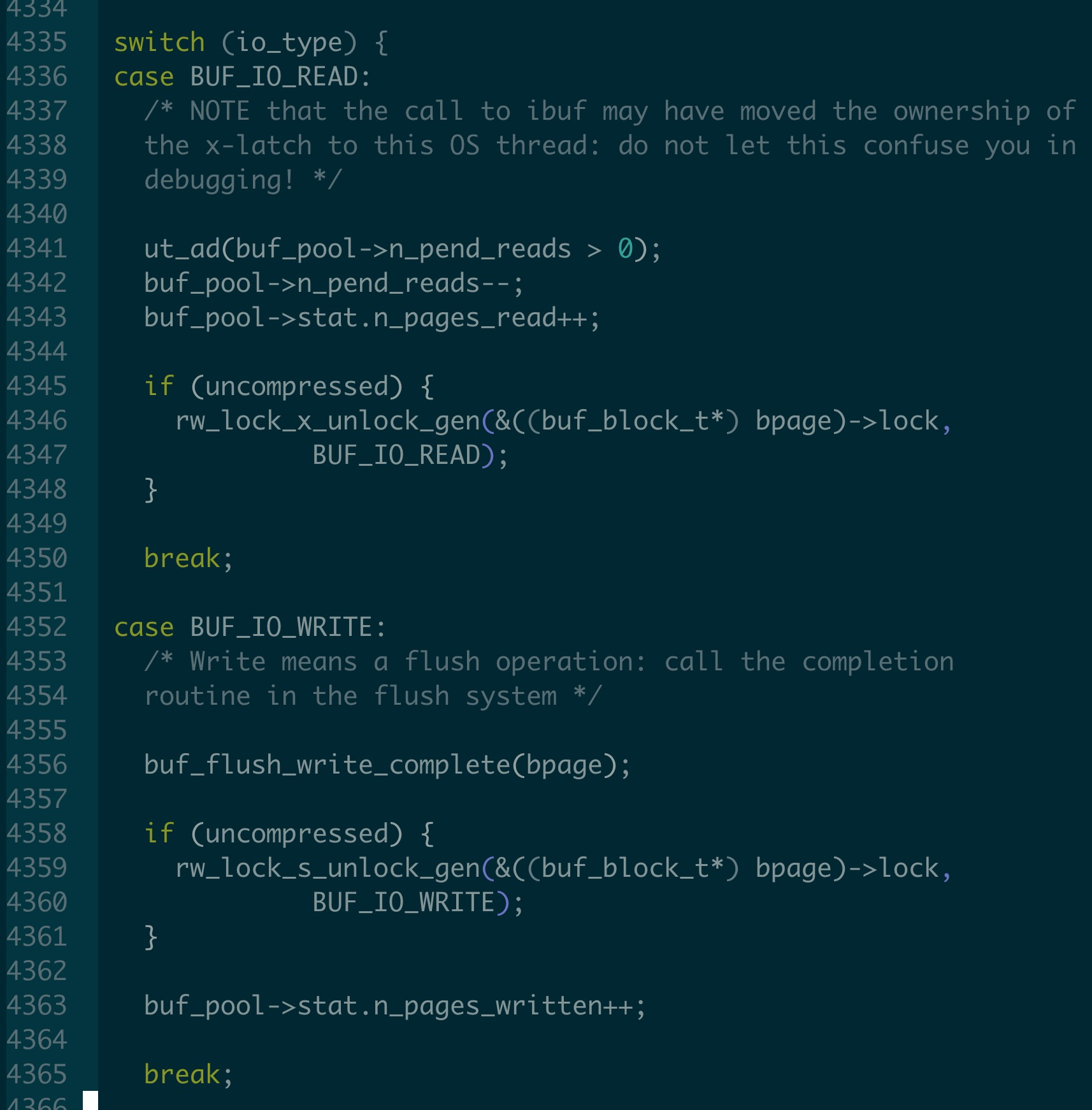
io_fix 表示当前的page frame 正在进行的IO 操作状态, 主要有 BUF_IO_READ, BUF_IO_WRITE, BUF_IO_PIN, BUF_IO_NONE.
BUF_IO_READ: 当前Page 正在从disk 读取到buffer pool 中.
BUF_IO_WRITE: 当前Page 正在从buffer pool 写入到disk 中. 在 buf_flush_page() 函数执行刷脏的时候设置.
一旦IO 操作结束, 在 buf_page_io_complete() io_fix 会被设置成 BUF_IO_NONE.
buf_fix_count 表示当前这个block 被引用了多少次, 每次访问一个page 的时候, 都会对buf_fix_count++, 最后在mtr:commit() 的最后资源释放阶段, 会对这个buf_fix_count–, 进行资源的释放.
比如: 在flush 一个page 的时候, 会检测一个page 是否可以被flush, 这里为了减少拿 page frame rw_lock, 直接通过判断 io_fix 即可
if (bpage->oldest_modification == 0 ||
buf_page_get_io_fix_unlocked(bpage) != BUF_IO_NONE) {
return (false);
}
比如: 在检查一个block 能否被replace 的时候, 除了确定当前这个block io_fix == BUF_IO_NONE, 还需要确保当前没有其他的线程在引用这个block, 当然还需要保证当前block oldest_modification ==0. 来确定当前这个block 是否可以允许被replace
ibool buf_flush_ready_for_replace(buf_page_t *bpage) {
if (buf_page_in_file(bpage)) {
return (bpage->oldest_modification == 0 && bpage->buf_fix_count == 0 &&
buf_page_get_io_fix(bpage) == BUF_IO_NONE);
}
}
可以理解, 引入io_fix, buf_fix_count 是为了减少调用page frame rw_lock 的开销, 因为page frame 的调用是在btree search 的核心路径
如果io_fix 处于BUF_IO_READ, BUF_IO_WRITE 那我们可以知道, 当前page 处于IO 状态, 如果要进行replace, flush 操作是不可以的, 这样就不需要去获得page frame rw_lock, 然后再检查当前page frame 是否允许这样的操作
所以代码里面我们会看到在设置了io_fix 的状态以后, 我们就可以把之前的几个mutex, rw_lock 都完全放开, 因为被设置了io_fix 状态的page 是不可以从list 上面删除或者replace, 需要等IO 操作完成以后, 将io_fix 设置成BUF_IO_NONE 才可以进行操作
BPageLock lock rw_lock
如上所说, BPageMutex 是保护buf_block_t 结构体, 而BPageLock 是为了保护page frame. 当需要对buffer pool page frame 内容进行读取/修改的时候, 就需要持有BPageLock.
比如最常见的我们要修改一个btree page 内容的时候, 都需要通过btr_cur_search_to_nth_level() 把page 从磁盘读取到内存中, 然后修改. 这里修改之前会对page 加 x lock. 如果是读取操作, 就需要加s lock.
同样后台进行刷脏操作的时候, 在进行具体 IO write 操作阶段, 对 page 加s lock. 在进行具体的从磁盘读取到buffer pool 阶段, 对page 加 x lock.
这里要区分进行IO 过程中对rw_lock 的用途. 以及正常没有进行IO 操作的时候, btr_cur_search_to_nth_level() 对bp 中的page s/x lock 的用途.
在InnoDB 访问btree 的过程中, btr_cur_search_to_nth_level() 函数里面, 会对btree index s lock, 如果只是修改leaf page, 那么在8.0 里面, 是沿着btree 的搜索路径, 给路径上的non-leaf page 都加上s lock, 最后给leaf page 加x lock. 具体看文章 InnoDB latch
但是后台操作比如刷脏, 或者当前page frame 不在buffer pool 中, 同样需要拿 page frame rw_lock, 那么是会对前台的page 访问有非常大的性能影响. 因此上述的io_fix, page block mutex 也是为了尽可能减少持有page frame rw_lock 的机会
我们看到官方做了很多优化, 比如尽可能减少访问btree 的时候, 拿着btree index lock, 在访问btree 的时候, 不会像在5.6 时候一样, 拿着整个btree index lock.
这里与5.6 对比, 5.6 在做SMO 的时候, 是所有的读操作也无法进行的, 因为读操作都需要加 index s lock..
在8.0 在做SMO 的时候, 因为index 加的是sx lock, 所以所有的读操作依然是可以进行的, 但是由于sx lock 和 sx lock 之间是互斥的, 因此同一时刻只能有一个smo 在进行. 但是这也比5.6 好很多, 至少在SMO 的过程, 读操作还可以进行的
但是8.0 里面还有一个约束就是同一时刻只能有一个SMO 正在进行, 因为SMO 的时候需要拿 sx lock. 这也是目前8.0 主要问题.
(其实引入sx lock 是对读取的优化, 对写入并没有优化. 因为持有sx lock 的时候, s lock 操作是可以进行的, 但是x lock 操作是不可以进行的. 跟原先需要修改就直接拿着x lock 对比, 允许更多的读取了, 但是x lock 和之前是一样的)
但是这些优化只是优化了用户访问路径上page frame rw_lock 的获取, 但是在后台的路径并没有过多的优化.
比如: page frame rw_lock 是在buf_page_io_complete 之后才会放开的
在page flush, read ahead 的时候, 在走simulated AIO 的时候, page 操作被放入队列即可, 但是并没有执行完成.
执行完成的通知是在simulated AIO fil_aio_wait:buf_page_io_complete() 里面完成, 在buf_page_io_complete() 操作里面, 会把page 上的rw_lock 给释放.
所以一个page 在进行IO 操作的时候, 是在调用simulated AIO 之前, 给page frame rw_lock 加 x/sx lock, 但是释放page frame rw_lock 需要等到IO 操作结束才可以完成, 而fio_io() 只是将IO 放到的队列中, 这个IO 并没有执行完成. 是在simulated io handler 的 fil_aio_wait() 函数里面, 这个操作才会完成, 然后调用buf_page_io_complete() 进行通知操作.
因此page frame 的rw_lock 的持有周期是整个异步IO 的周期, 直到IO 操作完成, 这个page frame 才会释放.
而page frame 的rw_lock 又是用户访问btree 路径上面的 btr_cur_search_to_nth_level() 必须要获得的lock, 因此就可能出现大量的page frame由于刷脏或者read ahead 的时候, 持有了page frame x lock/sx lock, 当用户的访问路径需要x/sx lock 的时候, 被堵塞住的情况.
这种堵塞住的情况, 如果是非leaf page 的时候, 影响会更明显, 而且目前InnoDB simulated AIO 的队列长度是*(n_read_thread + n_write_thread) * 256, 那么会可能出现大量的page 因为在IO 等待队列中等待, 造成更多的btree search 操作被堵住, 特别是如果底层存储IO latency 比较长的情况, 这里问题会更加的明显.
当然我们也通过simulated AIO 优化, copy page等等减少持有page frame 的时长.
buf_page_io_complete 主要做什么呢?
同步IO 和 异步IO 操作都会调用 buf_page_io_complete.
同步read 操作buf_read_page_low sync=true 最后会调用
同步write 操作 buf_flush_write_block_low sync=true 也会调用, 当然只有single page flush 才会同步刷脏
buf_page_io_complete 主要工作:
将page io_fix 设置成NONE, 表示这个page 的io 操作已经完成了.
buf_page_set_io_fix(bpage, BUF_IO_NONE);
另外重要的是IO 操作完成以后, 因此buf_page_io_complete 是完成异步的IO 操作, 那么就需要唤醒等待在这个IO 的线程.
如果是读操作, 要注意的是, 在这里才会将page x lock 放开.
如果是写操作, 执行buf_flush_write_complete() 将 flush list, LRU list 上的page 删除等等操作, POLARDB 的copy page 也在这里进行删除操作
将page 上面的rw_lock 放开, 如果是read, 把 x lock 放开, 如果是write, 把sx lock 放开.
为什么是这样? 那么什么时候拿s lock?
read 操作要拿page x lock 因为read操作会从磁盘中读取数据, 会修改page 里面的内容, 另外为了避免多个线程同时去读这个page, 然后另外一个线程如果需要访问该page, 那么会通过buf_wait_for_read(block) 操作, 尝试给这个page frame 加s lock, 如果加成功, 这说明这个page 已经被获得了
write 操作要拿page s lock. 在5.7/8.0 以后持有的是sx lock. 因为write 操作不会修改page 中的内容, 但是需要防止有人在write page 的时候对page 进行修改.
那么这些latch 是如何保证并发访问控制的时候不会出现死锁呢?
在InnoDB 里面定义了所有latch 的latch order, 所有thread 都按照这个顺序进行加锁, 那么就不会出现死锁情况, 其中对于InnoDB buffer pool 这块的latch 是这样的顺序
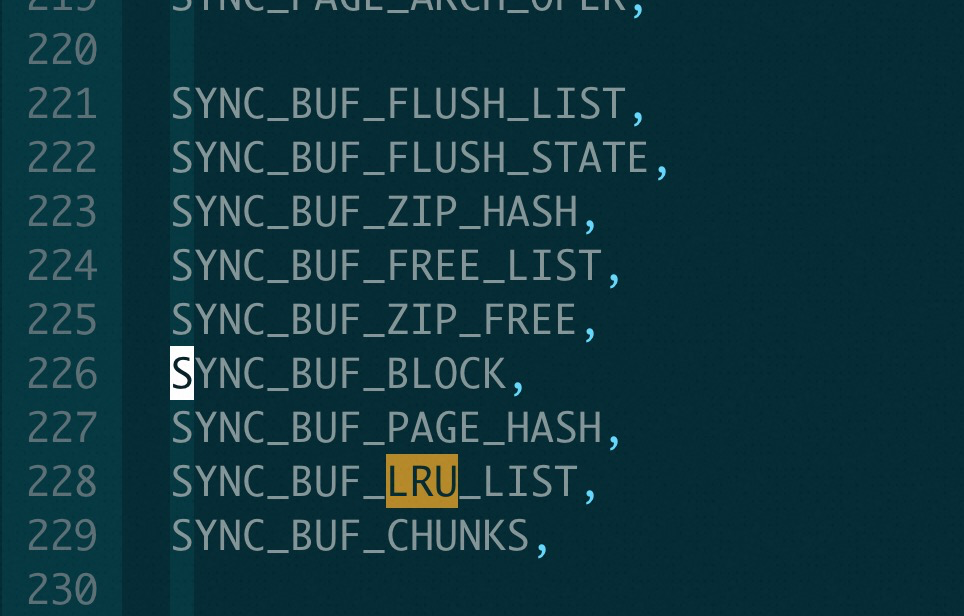
比如:
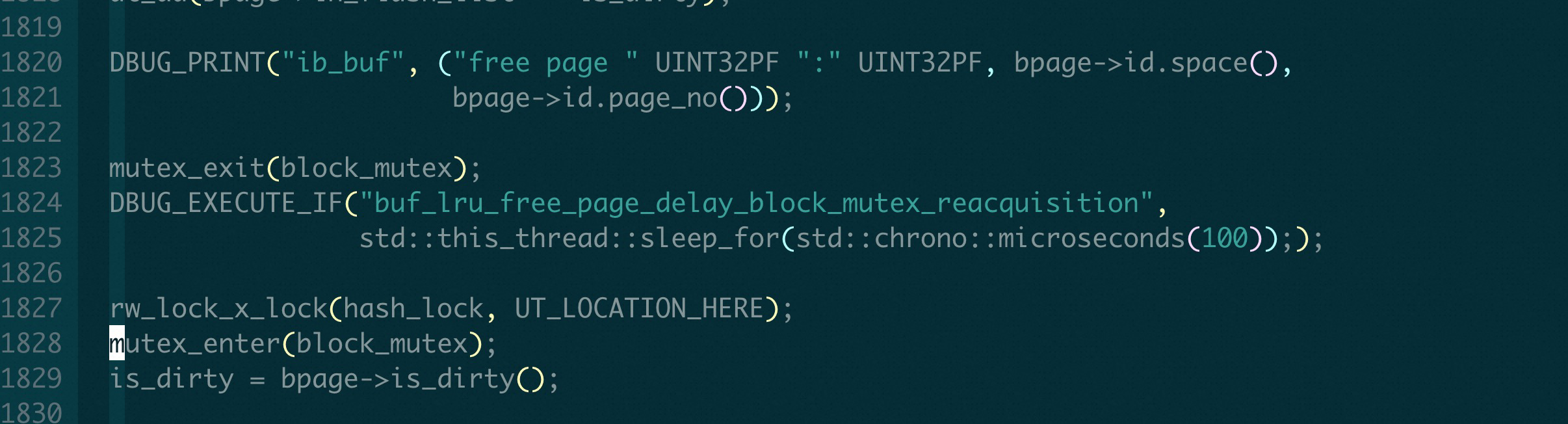
在 buf_LRU_free_page() 里面, 为了加hash_lock (SYNC_BUF_PAGE_HASH) mutex, 因为已经持有block_mutex(SYNC_BUF_BLOCK), 就必须先释放block_mutex(SYNC_BUF_BLOCK), 然后再重新加上.
可以看到上述的latch order 是BUF_LRU_LIST => BUF_BLOCK => BUF_FLUSH_LIST, 而不是BUF_LRU_LIST => BUF_FLUSH_LIST => BUF_BLOCK. 为啥要把flush_list 的latch 放在buf_block 后面呢?
因为这样的顺序会出现很奇怪的代码.
比如 buf_flush_batch 函数里面, 对lru list 刷脏的时候需要提前持有 list_list mutex, 但是对flush list 刷脏的时候不需要持有flush list mutex? 这里是严格按照latch order 定义的, 但是为什么latch order 要这样设定呢?
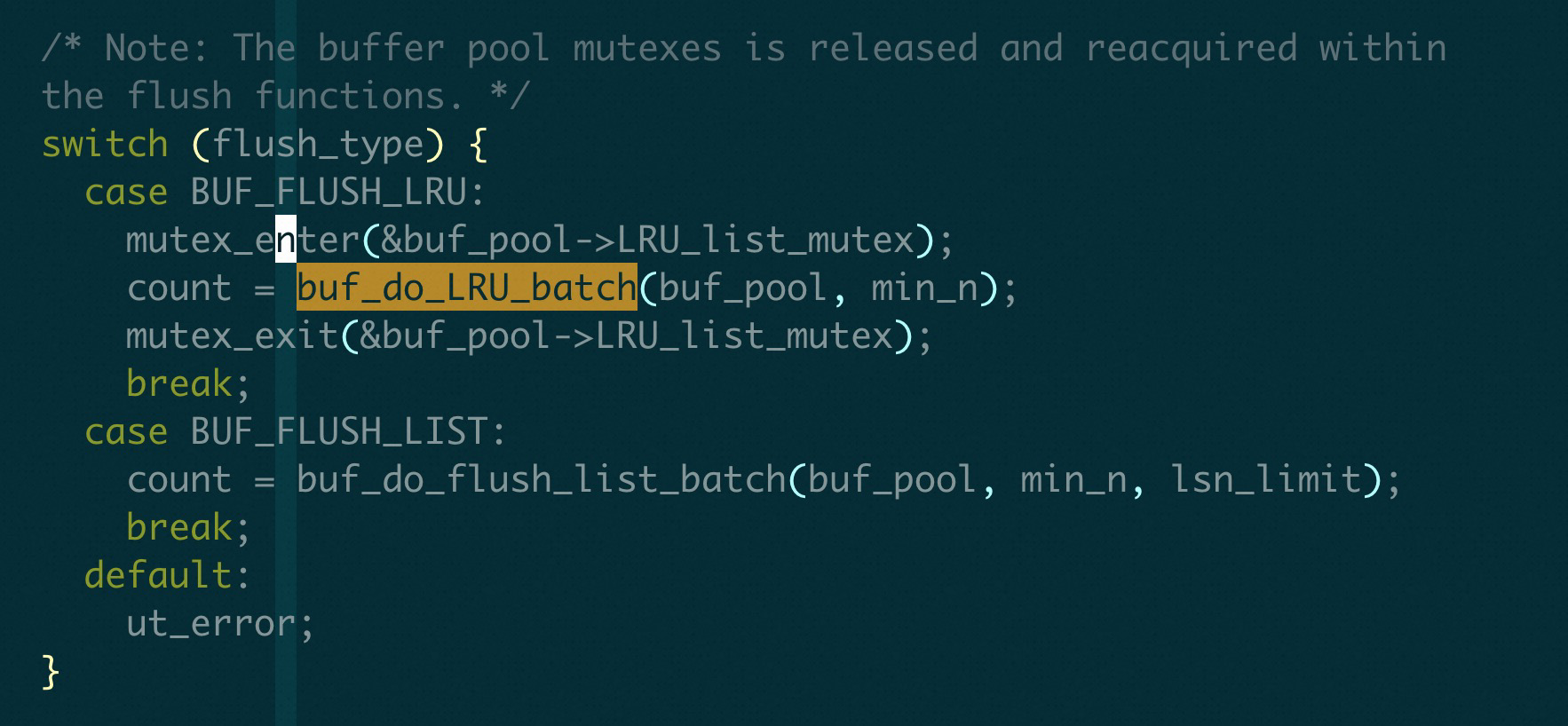
我理解最常见的操作流程是这样的
对Btree 的修改: 先从LRU_list 找一个free block 的时候持有LRU list, 拿到block 以后持有block latch, 最后要去flush list 上面修改, 持有flush list. 这样就顺序就是latch order 里面的顺序,
但是其他场景就只能按照这个顺序了, 所以代码里面经常出现这种 持有 flush_list mutex 的时候, 要想获得block_mutex, 需要先释放一下 flush_list mutex.
在buf_flush_page_and_try_neighbors() 里面, buf_flush_try_neighbors() 是需要持有block latch, 那么就需要提前将flush_list mutex 释放, 当然这里释放flush_list mutex 也为了避免进行IO 过程持有flush_list mutex 过长时间.
所以在Buffer Pool 的代码里面, 出现非常多的针对LRU_list 和 flush_list 不同的处理方式, 比如在持有LRU_list 以后可以直接持有block_mutex, 但是持有flush_list 则不可以等等.
总结:
free/LRU/flush List 相关mutex 主要是是否操作 list 时候持有.
而后面4个mutex 一般操作都是加hash_lock rw_lock, 然后获得buf block mutex, 放开hash_lock rw_lock, 然后修改 io_fix, buf_fix_count,然后放开 buf block mutex, 最后持有page frame rw_lock.
如上面所说寻找block 在hash table 的位置, 通过hash_lock slot 级别的Lock 来进行了优化, 减少了修改和查找hash table 的冲突
引入 buf block mutex, io_fix, buf_fix_count 将IO操作通过判断io_fix, buf_fix_count 避免不必要的获得page frame rw_lock 的开销.
具体代码流程
buf_page_init_for_read
以 buf_read_page_low() => buf_page_init_for_read() 来举例并发过程
-
// 根据page_id 返回对应的buf_pool instance buf_pool_t *buf_pool = buf_pool_get(page_id);
// 先尝试从LRU list 获得一个free block block = buf_LRU_get_free_block(buf_pool);
// 持有我们说的第一层 LRU_list_mutex mutex_enter(&buf_pool->LRU_list_mutex);
-
// 然后持有我们说的第二层 hash_lock hash_lock = buf_page_hash_lock_get(buf_pool, page_id); rw_lock_x_lock(hash_lock);
-
// 持有page block mutex buf_page_mutex_enter(block);
-
// 在持有page block mutex 的情况下, 会修改 block->state, io_fix 等等
buf_page_init(buf_pool, page_id, page_size, block);
buf_page_set_io_fix(bpage, BUF_IO_READ);
// 将当前Block 加入到LRU list 中
buf_LRU_add_block(bpage, TRUE /* to old blocks */);
// 释放 LRU list mutex, 这里持有LRU list mutex 到现在, 是因为要把page block 加入到LRU list中
mutex_exit(&buf_pool->LRU_list_mutex);
-
// 这里给page frame 加了rw_lock x lock, // 保证同一时刻只会有一个线程从磁盘去读取这个page
rw_lock_x_lock_gen(&block->lock, BUF_IO_READ);
// 依次放开hash_lock rw_lock rw_lock_x_unlock(hash_lock); // page block mutex buf_page_mutex_exit(block);
buf_page_try_get_func
比如在 buf_page_try_get_func() 函数里面, 也是这样顺序获得mutex 的操作.
// 1. 首先获得这个bp, 因此这里不涉及到各个list 相关操作, 因此没有list // 相关Mutex buf_pool_t *buf_pool = buf_pool_get(page_id);
// 2. 获得这个page 在hash table 上面的slot 上面的block, // 同时在这个函数里面, 已经把这个hash_lock 给s lock 了 block = buf_block_hash_get_s_locked(buf_pool, page_id, &hash_lock);
// 3. 或者这个page block block mutex, 同时将这里的hash_lock 给释放 buf_page_mutex_enter(block); rw_lock_s_unlock(hash_lock);
// 4. 在持有page block mutex 之后, 给这个block buf_fix_count++, 同时把这个page block mutex 释放 // 这里设置了buf_fix_count 之后, 上述的mutex, rw_lock 都放开了, 因为这个page frame 在buf_fix_count != 0 的情况下, 是不能被replace 的, 会议在在buffer pool 里面, 因此后续的page frame s lock 操作可以放心操作
buf_block_buf_fix_inc(block, file, line); buf_page_mutex_exit(block);
// 5. 获得这个page frame 的rw_lock mtr_memo_type_t fix_type = MTR_MEMO_PAGE_S_FIX; success = rw_lock_s_lock_nowait(&block->lock, file, line);
在写入操作里面
buf_flush_page_and_try_neighbors
在执行刷脏的时候, 可能从LRU_list, flush_list 上面刷脏, 分别是
buf_do_LRU_batch, buf_do_flush_list_batch
这两个函数都会调用 buf_flush_page_and_try_neighbors 进行刷脏操作, 这里在进行具体page 刷脏操作过程中是会将 lru_list_mutex/flush_list_mutex 放开, 然后操作完成以后再持有
if (flush_type == BUF_FLUSH_LRU) {
mutex_exit(&buf_pool->LRU_list_mutex);
}
if (flush_type == BUF_FLUSH_LRU) {
mutex_exit(block_mutex);
} else {
buf_flush_list_mutex_exit(buf_pool);
}
// 在进行具体flush 操作的时候, 是会将LRU_list_mutex/buf_flush_list mutex放开
*count += buf_flush_try_neighbors(page_id, flush_type, *count, n_to_flush);
if (flush_type == BUF_FLUSH_LRU) {
mutex_enter(&buf_pool->LRU_list_mutex);
} else {
buf_flush_list_mutex_enter(buf_pool);
}
具体的page flush 操作
**buf_flush_try_neighbors => buf_flush_page **
// 1. 首先获得 hash_lock rw_lock
/* We only want to flush pages from this buffer pool. */
bpage = buf_page_hash_get_s_locked(buf_pool, cur_page_id, &hash_lock);
// 2. 然后是获得page header mutex, 同时释放hash_lock
block_mutex = buf_page_get_mutex(bpage);
mutex_enter(block_mutex);
rw_lock_s_unlock(hash_lock);
// => 进入buf_flush_page()
// 3. 修改 io_fix 设置成 BUF_IO_WRITE
buf_page_set_io_fix(bpage, BUF_IO_WRITE);
// 4. 放开buf block mutex
// 因为已经修改了 io_fixed 和 oldest_modification
// 因此到这里已经不需要持有任何mutex 了
mutex_exit(block_mutex);
// 5. 获得这个page frame 的 rw_lock
rw_lock_sx_lock_gen(rw_lock, BUF_IO_WRITE);
// 对这个page 进行flush 操作的时候, 不需要持有mutex
buf_flush_write_block_low(bpage, flush_type, sync);