InnoDB btree latch 优化历程
(一般在数据库里面latch 指的是物理Lock, Lock 指的是事务的逻辑lock, 这里混用)
在InnoDB 的实现中, btree 主要有两种lock: index lock 和 page lock
index lock 就是整个Index 的lock, 具体在代码里面就是 dict_index->lock
page lock 就是我们在btree 里面每一个page 的变量里面都会有的 lock
当我们说btree lock的时候, 一般同时包含 index lock 和 page lock 来一起实现
在5.6 的实现里面比较简单,btree latch 大概是这样的流程
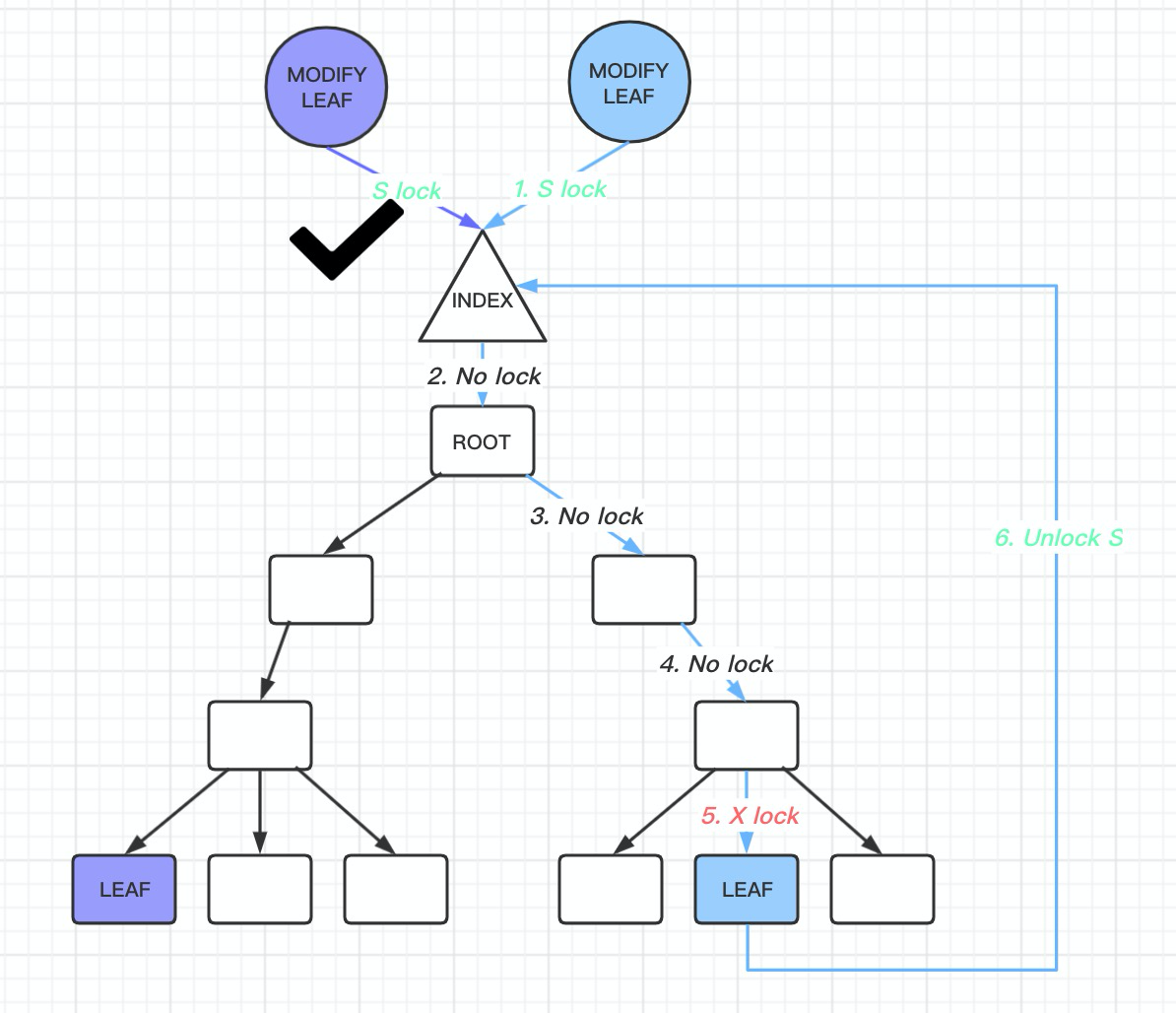
- 如果是一个查询请求
-
那么首先把btree index->lock S LOCK
-
然后直到找到 leaf node 以后, 对leaft node 也是 S LOCK, 然后把index-> lock 放开
-
- 如果是一个修改leaf page 请求
- 同样把btree index-> lock S LOCK
- 然后直到找到leaf node 以后, 对leaf node 执行 X LOCK, 因为需要修改这个page. 然后把index->lock 放开. 到这里又分两种场景了, 对于这个page 的修改是否会引起 btree 的变化
-
如果不会, 那么很好, 对leaf node 执行了X LOCK 以后, 修改完数据返回就可以
-
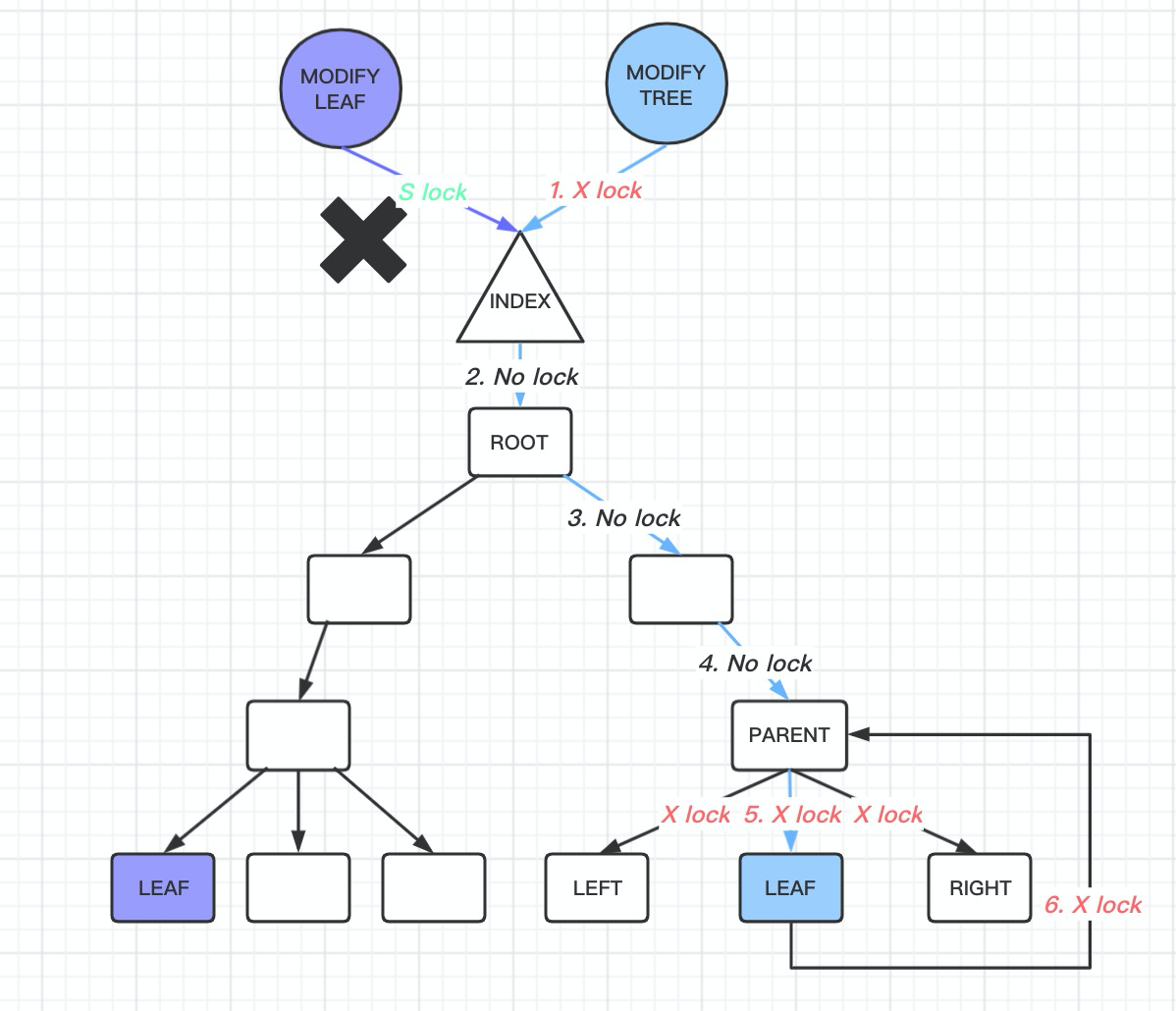
如果会, 那么需要执行悲观插入操作, 重新遍历btree.
对btree inex 加X LOCK, 执行btr_cur_search_to_nth_level 到指定的page.
因为leaft node 修改, 可能导致整个沿着leaf node 到root node 的btree 都会随着修改, 因此必须让其他的线程不能访问到, 因此需要整个btree 加X LOCK, 那么其他任何的查询请求都不能访问了, 并且加了index X LOCK 以后, 进行record 插入到page, 甚至可能导致上一个Level 的page 也需要改变, 这里需要从磁盘中读取数据, 因此可能有磁盘IO, 这就导致了加X LOCK 可能需要很长一段时间, 这段时间sread 相关的操作就都不可访问了
这里具体的代码在 row_ins_clust_index_entry
首先尝试乐观的插入操作
err = row_ins_clust_index_entry_low( 0, BTR_MODIFY_LEAF, index, n_uniq, entry, n_ext, thr, &page_no, &modify_clock);
然后这里如果插入失败, 再尝试悲观的插入操作,
return(row_ins_clust_index_entry_low( 0, BTR_MODIFY_TREE, index, n_uniq, entry, n_ext, thr, &page_no, &modify_clock));
从这里可以看到, 唯一的区别在于这里latch_mode = BTR_MODIFY_LEAF 或者 BTR_MODIFY_TREE. 并且由于btr_cur_search_to_nth_level 是在函数 row_ins_clust_index_entry_low 执行, 那么也就是尝试了乐观操作失败以后, 重新进行悲观插入的时候, 需要重新遍历btree
-
从上面可以看到, 5.6 里面只有对整个btree 的index lock, 以及在btree 上面的leaf node page 会有lock, 但是btree 上面non-leaf node 并没有 lock.
这样的实现带来的好处是代码实现非常简单, 但是缺点也很明显由于在SMO 操作的过程中, 读取操作也是无法进行的, 并且SMO 操作过程可能有IO 操作, 带来的性能抖动非常明显, 我们在线上也经常观察到这样的现象.
所以有了官方的改动, 其实这些改动在5.7 就引入, 我们这里以8.0 为例子:
主要有这两个改动
- 引入了sx lock
- 引入了non-leaf page lock
引入SX Lock 以后
首先介绍一下 SX Lock, SX Lock 在index lock 和 page lock 的时候都可能用到.
SX Lock 是和 S LOCK 不冲突, 但是和 X LOCK 冲突的, SX LOCK 和 SX LOCK 之间是冲突的.
SX LOCK 的意思我有意向要修改这个保护的范围, 但是现在还没开始修改, 所以还可以继续访问, 但是要修改以后, 就无法访问了. 因为我有意向要修改, 因此不能允许其他的改动发生, 因此和 X LOCK 是冲突的.
目前主要用途因为index SX lock 和 S LOCK 不冲突, 因此悲观insert 改成index SX LOCK 以后, 可以允许用户的read/乐观写入
SX LOCK 的引入由这个 WL 加入 WL#6363
可以认为 SX LOCK 的引入是为了对读操作更加的优化, SX lock 是和 X lock 冲突, 但是是和 S lock 不冲突的, 将以前需要加X lock 的地方改成了SX lock, 因此对读取更加友好了
引入non-leaf page lock
其实这也是大部分商业数据库都是这样, 除了leaf page 有page lock, non-leaf page 也有page lock.
主要的想法还是 Latch coupling, 在从上到下遍历btree 的过程中, 持有了子节点的page lock 以后, 再把父节点的page lock 放开, 这样就可以尽可能的减少latch 的范围. 这样的实现就必须保证non-leaf page 也必须持有page lock.
不过这里InnoDB 并未把index->lock 完全去掉, 这就导致了现在InnoDB 同一时刻仍然只有同时有一个 BTR_MODIFY_TREE 操作在进行, 从而在激烈并发修改btree 结构的时候, 性能下降明显.
回到5.6 的问题
可以看到在5.6 里面, 最差的情况是如果要修改一个btree leaf page, 这个btree leaf page 可能会触发btree 结构的改变, 那么这个时候就需要加一整个index X LOCK, 但是其实我们知道有可能这个改动只影响当前以及上一个level 的btree page, 如果我们能够缩小LOCK 的范围, 那么肯定对并发是有帮助的.
那么到了8.0
-
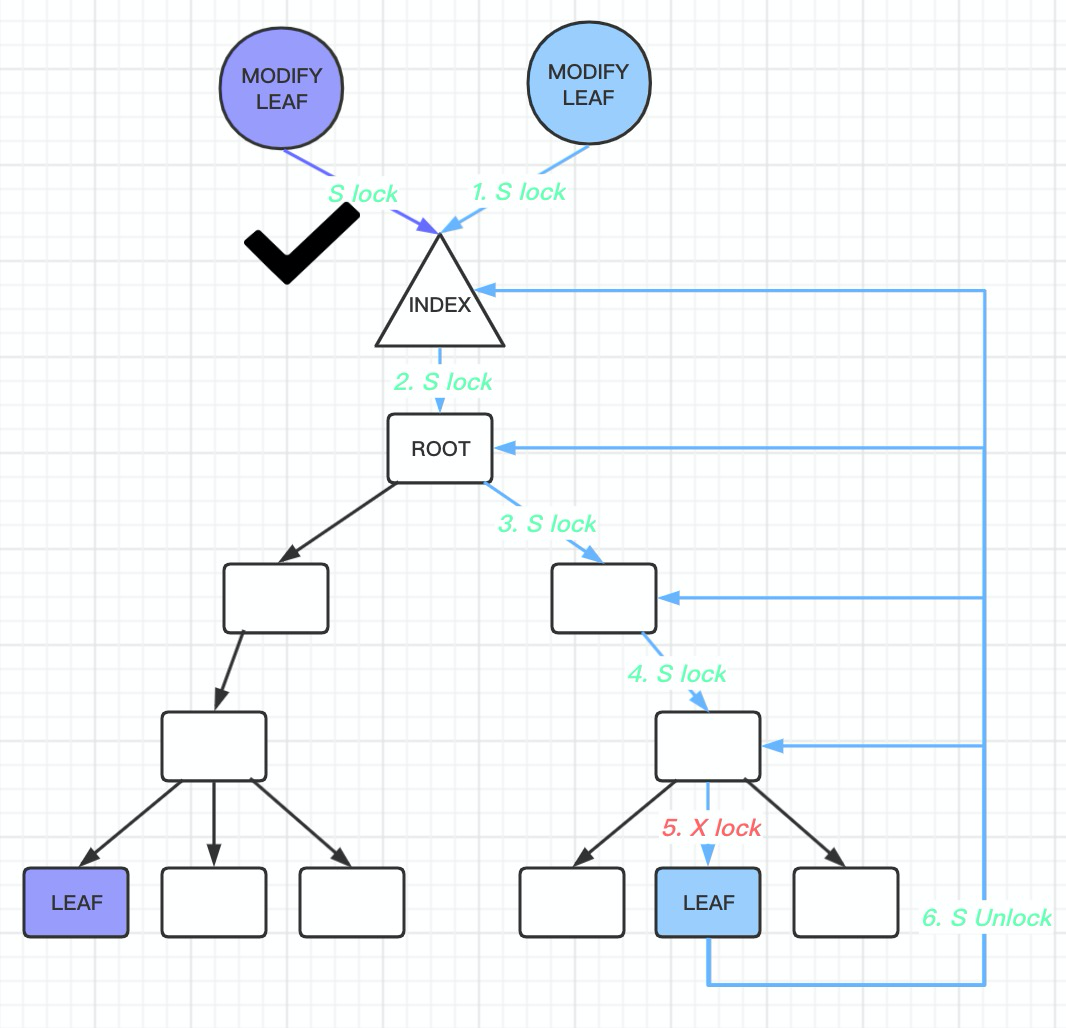
如果是一个查询请求
-
那么首先把btree index->lock S LOCK
-
然后沿着搜索btree 路径, 遇到的non-leaf node page 都加 S LOCK
-
然后直到找到 leaf node 以后, 对leaft node page 也是 S LOCK, 然后把index-> lock 放开
-
-
如果是一个修改leaf page 请求
-
同样把btree index-> lock S LOCK, 通过对non-leaf node page 都加S LOCK
-
然后直到找到leaf node 以后, 对leaf node 执行 X LOCK, 因为需要修改这个page. 然后把index->lock 放开. 到这里又分两种场景了, 对于这个page 的修改是否会引起 btree 的变化
-
如果不会, 那么很好, 对leaf node 执行了X LOCK 以后, 修改完数据返回就可以
-
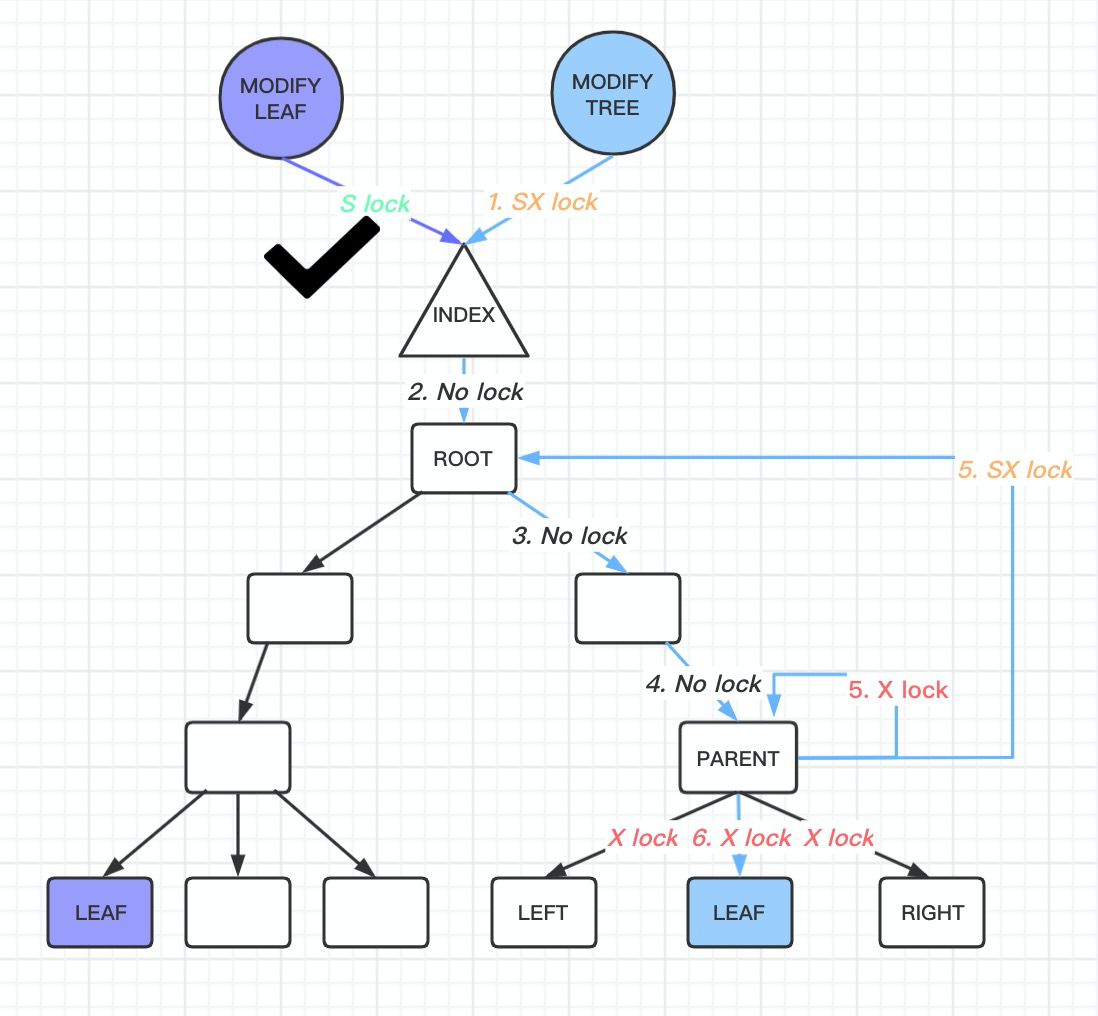
如果会, 那么需要执行悲观插入操作, 重新遍历btree. 这时候给index->lock 是加 SX LOCK
因为已经给btree 加上sx lock, 那么搜索路径上btree 的page都不需要加 s lock, 但是需要把搜索 btree 过程中的page 保存下来, 最后这次SMO 导致的btree 分裂可能只有一部分, 所以只需要对这部分page加x lock就够了.
这样就保证了在搜索的过程中, 对于read 操作的影响降到最低.
只有在最后阶段确定了本次修改btree 结构的范围, 对可能发生结构变化的page 加X lock 以后, 才会有影响.
-
8.0 里面, SMO 操作过程中, 拿着sx lock 的持续时间是
加上sx lock 的时间:
第一次btr_cur_optimistic_insert insert 失败以后, 在 row_ins_clust_index_entry 会调用
row_ins_clust_index_entry_low(flags, BTR_MODIFY_TREE …) 进行插入, 在 row_ins_clust_index_entry_low 里面, 在btr_cur_search_to_nth_level 函数里面加上 sx lock, 到这里btree 因为已经加了sx lock, 就已经无法进行smo 操作了, 然后接下来仍然会尝试先乐观插入,这个时候sx lock 依然持有, 失败的话, 再尝试悲观插入操作.
释放sx lock 的时间:
在悲观插入操作里面会一直持有sx lock, 直到在 btr_page_split_and_insert 内部, 将新的page2 已经产生, 同时page2 已经连接上father node 之后. 并且这次发生SMO 的page 还需要是leaf page, 否则一直持有sx lock, 直到SMO 操作完成, 并且insert 成功才会释放
具体执行SMO 操作并且insert 的函数是 btr_page_split_and_insert
btr_page_split_and_insert 操作大概有8个流程:
-
从要分裂的page 中, 找到要split 的record, split 的时候要保证split 的位置是record 的边界
-
分配一个新的索引页
-
分别计算page, 和new_page 的边界record
-
在上一级索引页(父节点)添加新的索引页的索引项, 如果上一级没有足够的空间, 那么就触发父节点的分裂操作了
-
连接当前索引页, 当前索引页prev_page, next_page, father_page, 新创建的 page. 当前的连接顺序是先连接父节点, 然后是prev_page/next_page, 最后是 page 和 new_page (在这一步结束之后就可以放开index->sx lock)
-
将当前索引页上的部分Record 移动到新的索引页
-
SMO 操作已经结束, 计算本次insert 要插入的page 位置
-
进行insert 操作, 如果insert 失败, 通过reorgination page 重新尝试插入
-
-
-
现有代码里面只有一个场景会对index->lock X lock. 也就是
if (lock_intention == BTR_INTENTION_DELETE &&
trx_sys->rseg_history_len > BTR_CUR_FINE_HISTORY_LENGTH &&
buf_get_n_pending_read_ios()) { 如果这次lock_intention 是BTR_INTENTION_DELETE, 并且history list 过长, 才会对 index 加 x lock
总结:
8.0 比5.6 改进的地方
在5.6 里面, 写入的时候, 如果有SMO 在进行, 那么就需要把整个index->lock x lock, 那么在SMO 期间所有的read 操作也是无法进行的.
在8.0 里面SMO 操作的过程中是允许有read 和 乐观写入操作的.
但是8.0 里面还有一个约束就是同一时刻只能有一个SMO 正在进行, 因为SMO 的时候需要拿 sx lock. sx lock 和 sx lock 是冲突的, 这也是目前8.0 主要问题.
优化点
当然这里还是有优化点.
-
依然有全局的index->lock, 虽然是sx lock, 但是理论上按照8.0 的实现, 可以完全将index lock 放开, 当然很多细节需要处理
-
在执行具体的分裂操作过程中, btr_page_split_and_insert 里面的持有index lock 是否还可以优化?
-
比如按照一定的顺序的话, 是否将新创建page 连接到new_page 以后就可以放开index->lock
-
还可以考虑发生SMO 的page 持有x lock 的时间.
目前会持有整个路径上的page x lock 直到SMO 操作结束, 并且这次insert 完成, 同时需要一直持有fater_page, prev_page, next_page 的x lock, 是否可以减少持有page 的个数, 比如这个优化 BUG#99948
-
btr_attach_half_pages 中多次通过btr_cur_search_to_nth_level 遍历btree 操作是否可以避免? 函数是将father link, prev link, next link 等建立好的操作 在这里会重新执行一次 btr_page_get_father_block 对btree 进行遍历找到父节点, 在该函数里面有需要重新执行 btr_cur_search_to_nth_level 函数, 其实这一步操作是可以避免的. 因为这时index已经 sx lock 了, father 肯定不会变了的, 那么可以将上次btr_cur_search_to_nth_level 的结果保留, 就可以获得
-
是否可以像b-link tree 类似, 给正在SMO 的page 标记状态, 这个状态是允许读取的, 只不过有可能存在要读取的record 不在当前的page, 那么就需要去该page->next page 去尝试读取, 如果能读取到依然是可以的..
-
-
每次进行btr_cur_search_to_nth_level, 搜索路径中遇到的page 是否可以保留? 这样即使重复搜索, 只需要确定upper level page 的max trx_id, 则可以确定整个搜索路径都没有改变, 那么就不需要重新遍历.
-
是否还需要保留先乐观insert 再悲观insert 的操作过程?
我理解现有的流程是因为在5.6 的实现中, 悲观insert 操作的开销太大, 从而尽可能的避免悲观insert, 因此沿用到了目前的8.0 实现中.这种多次insert 需要多次遍历btree, 带来额外开销
talking
https://dom.as/2011/07/03/innodb-index-lock/
https://dev.mysql.com/worklog/task/?id=6326