长路漫漫, 从Blink-tree 到Bw-tree (上)
天不生我 bw-tree, 索引万古如长夜
背景
在前面的文章 路在脚下, 从BTree 到Polar Index中提到, 我们已经将InnoDB 里面Btree 替换成Blink Tree, 高并发压力下, 在标准的TPCC 场景中最高能够有239%的性能提升, 然后我们对InnoDB 的file space模块也进行了优化, 在分配新page 的时候, 可以允许不进行填0 操作, 从而尽可能的减少fsp->mutex 的开销, 在这之后我们发现瓶颈卡在了page latch 上, 而且越是在多核的场景, page latch 的开销也越大.
目前latch 冲突的主要场景
-
读写冲突场景, 典型场景对Page 进行write 操作的时候, 另外一个read 操作进行要读取page.
-
写写冲突场景, 典型 autoinc, 或者update_index 对同一个page 进行更新场景.
-
“读读冲突”场景. 频繁的对btree root 附近level 进行s lcok 和 unlock 操作.
前面两个场景比较常见, 为什么会有读读冲突这样的问题?
现有 blink-tree + lock coupling 的实现中, 我们加锁的顺序是自上而下的, 每一次访问page 都需要lock, 然后unlock.
在InnoDB 自己实现的rw_lock中(大部分的rw_lock 实现也都类似), 每一个latch 都有lock_word 用于记录持有 s lock thread 数目, 所以即使是read 操作加s lock 的场景, 也是需要修改内存里面的 rw_lock->lock_word, 然后释放的时候继续对 lock_word 进行减1 操作.
这样带来的问题是在multi-core 场景中, 需要频繁的修改一个share memory(rw_lock->lock_word). 而对于share memory 的频繁修改会大量增加CPU cache coherence protocol.
即使 read only 的场景, 对于Blink-tree 的root page 依然有大量的s lock, s unlock 操作, 从而造成瓶颈.
在PolarDB 中, 这样的场景对我们的性能有多大的影响呢?
我们修改了InnoDB 代码, 在sysbench read_only 的场景下, 将所有的lock 都去掉 vs 仅仅持有s lock 的场景.
before 表示的是s lock 场景
after 表示的是不持有Lock 场景
因为是read_only 场景, 不会有任何数据写入, 所以不加锁也就不会出错
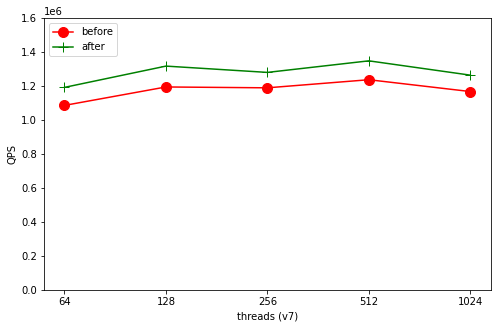
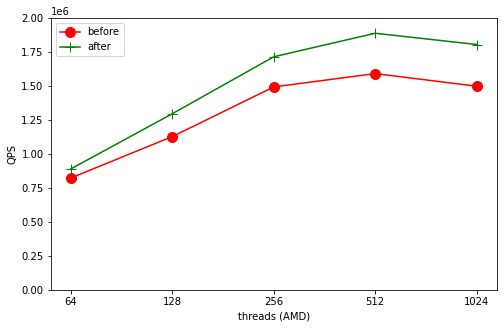
从上面两个图可以看到, 在Intel 128 core 的场景下, 不持有lock 的性能对比持有s lock 有10% 的提升, 在AMD 256 core 的场景下, 这个提升更加明显, 有20% 左右的提升.
所以我们认为这里在read only的场景中, 因为cache coherence protocol 引入的开销差不多有10%~20% 之间.
但是, 其实Btree 是一个非常扁平的tree, 绝大多数访问的是并不冲突的leaf page. 能否避免大家都去加锁访问root page 呢?
学术界如何处理Page 冲突的问题呢?
笔者主要参看CMU Advanced Database Systems 里面推荐的OLTP Indexex(B+Tree Data Structures) 和 OLTP Indexes (Trie Data Structures) 对这一块进行了解.
其实早在2001 年的时候, 在论文OLFIT 里面, 作者Cha 第一个提出简单的lock coupling 是无法在现代的multi-core CPU 进行scability 的. 即使在没有冲突的场景, 也会因为cache coherence protocol 的开销, 导致性能下降.
在OLFIT 文章里面, 介绍了这样的场景
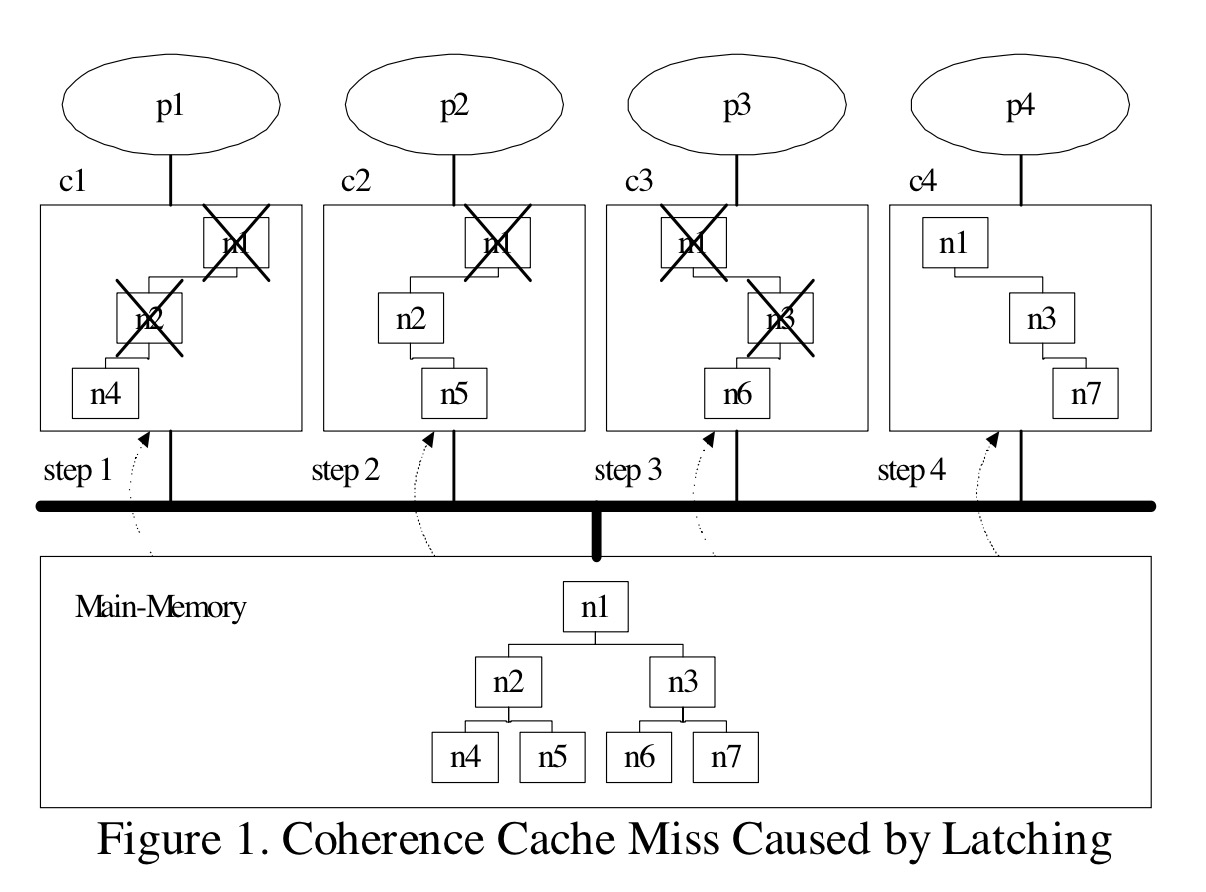
上图中, 在Main-Memory 里面有一个包含7个node btree, 为了简化问题, 有4个core, p1, p2, p3, p4. 有各种的cache block.
在初始的时刻, 所有core 里面的cacheline 都是空的, P1 访问的路径是 n1->n2->n4. 访问完以后, 会把n1, n2, n4 放在自己的cache block 中, 也会把对应的latch 放在自己的cache block 中. P2 访问的路径是n1->n2->n5. 在P2 访问n1, n2 的时候, 由于修改了n1 和 n2 的latch, 因此就必须增加了 Invalidate 在P1 里面的n1, n2 的latch 的开销, 同时如果P1 再次访问n1 的时候, 依然要重新冲main-memory 中去获得对应的latch. 并且这里可以看到c1 的cache block 即使有足够多的空间, 也依然会被Invalidate 掉的.
整体而言OLFIT 这个文章描述了Btree 在Multi-core 场景下的性能问题, 给出了一个较为简单的乐观加锁解决方案OLFIT.
OLFIT(Optimistic, Latch-Free Index Traversal CC)
OLFIT 实现读操作不需要加锁, 只有写操作需要加锁, 但是很重要的一个前提是, write 操作的修改一定要是原子性的.
OLFIT 大致流程:
Algorithm UpdateNode
Update 的算法:
U1. Acquire latch.
U2. Update the content.
U3. Increment version.
U4. Release latch.
Algorithm ReadNode
Read 的算法:
R1. Copy the value of version into a register R.
R2. Read the content of the node.
R3. If latch is locked, go to R1.
R4. If the current value of version is different fromthe copied value in R, go to R1.
Update 的算法:
操作的时候, 修改之前对page 进行lock, 然后修改完成以后增加版本号, 最后放锁.
Read 的算法:
整体Read 过程是不需要加锁的.
R1 操作将page 内容拷贝到本地, R2 读取内容.
由于OLFIT不对page 进行lock 操作, Read 进行R2 操作的时候, 有可能有新的Update 操作进来, 进行U2 操作, 也就是修改了page 里面的内容. 因此OLFIT需要在读操作完成以后, 通过R3/R4 操作, 判断Page 版本号是否被修改以及Page 是否被持有lock 来确认读取过程中该Page 是否被修改了, 如果被修改那么就需要发起重试操作了.
但是, 在工程上, 虽然最后R3/R4 会保证如果U2 进行了修改, Read 操作会进行重试, 但是如果这个U2 update非atomic, 会导致R2 读取出来的内容是corrupt 的. 所以在工程上必须保证U2 操作还应该是atomic 的. 但是目前看来在工程上是无法实现的.
比如现有 InnoDB 的 update the content 就是非atomic 的, 因为需要修改的是16kb 大小page 的内容. 那么读取操作有可能读取到了corrupt page, 那么这里就无法判断page corrupt 是由于真的page 出错导致corrupt, 还是由于读取非atomic 导致的corrupt. 当然可以通过重试来读取Page 来进一步验证, 但还是无法准确确定Page 的正确性.
所以这么看来在实际的工程实现中OLFIT 似乎是不可能实现的, OLFIT 很大的一个假设前提read content 是atomic 操作.
OLFIT 如何解决SMO 的问题?
Insert and delete operations can also initially acquire read locks before upgrading them to write locks if necessary.
并且由于read 操作可以不进行加s lock操作, 那么在btree 中进行x lock 加锁操作的时候自然可以自下而上了. 因为不存在之前search 自上而下的Lock, 而modify自下而上的Lock 导致的死锁问题了.
但是由于read 操作不再进行加锁操作, 那么可能在上述Algorithm ReadNode R2 操作中, Page 进行了split 操作. 即使我们能够保证Read Content of node 是原子操作, 也有可能该Page 发生了SMO 操作, 要访问的key 已经不在当前Page 了. 那么该如何处理?
目前OLFIT 通过和blink-tree 类似方法, 增加high key, 并且保证所有的SMO 操作是自左向右, 那么如果访问的page 发生了SMO 操作, 那么可以查看一下当前page 是否有high key, 如果有的话, 那么说明正在发生SMO 操作, 那么如果要访问的key 超过了high key, 那么就直接去访问next node 即可.
对于删除操作, 和大部分的无锁算法有点类似, Page 被删除以后无法确认没有其他的读取操作正在读取该Page, 因此目前的删除操作是将当前的Page 从当前Btree 中删除, 然后添加到garbage collector list 中. 后续有专门的garbage collector 线程进行garbage collector 操作.
在OLFIT 之后, Btree 在multi-core 场景下的性能问题也越来越热门, 并且随着现代CPU 技术的发展, CPU 上的core 数会越来越多, 因此该问题会随着core 数的增长愈发严重. 因此后面又有很多文章对该问题进行了探索, 典型的代表是 Bw-Tree 和 ART Tree.
我们先来看看ART Tree 怎么解决这样的问题.
ART Tree
ART Tree 其实提出了两个方案
- Optimistic Lock Coupling (OLC)
- Read-Optimized Write Exclusion (ROWEX)
OLC
OLC 的思想就是从 OLFIT 里面出来的, 但是OLFIT 最大的问题在于page version 一旦进行了修改就需要进行重试, 但是很多时候如果page 里面只是增加了数据, 并没有发生SMO, 其实是可以不用retry 的. 所以后续的masstree, ART tree 都是类似的思路.
另外一个优化是, OLC 可以在同一时刻snapshot 多个节点, 而OLFIT 可以认为同一时刻只能snapshot 1个节点的.
比如下图中, 右边是OLC 的流程, OLC 的流程是持有父节点的version, 然后去遍历子节点, 此刻最多持有2个节点的version, 当然也可以继续持有父节点的version 去遍历下一个子节点, 这样持有的snapshot 就是3个, 但是这样的并发就降低了.

但是这样OLC 还是有一个前提, 需要对page 的修改是atomic 的, 工程上依然是无法实现的.
工程上无法实现对page 的atomic 修改本质原因是当前的修改方案是Inplace update, 如果可以做non-inplace update修改, 那么就可以做到atomic 了. bw-tree 和 ROWEX 对Page 的修改就是这样的思路, 但是还是有细微的区别. 下面会讲到.
ROWEX
ROWEX 称为Read-Optimized Write EXclusion, 也就是Read 操作不需要加锁, 甚至不需要读取版本号, 但是写操作需要加锁.
ROWEX 和RCU 非常像, 读操作不需要任何加锁, 写操作需要加锁. 由于写操作不会对老page 进行修改, 所以读操作很容易实现 atomic, 但是读操作需要保证读取到的是旧版本的数据也能够处理. 对比OLC, 读取到旧版本就要retry 的行为, 性能肯定好很多.
ROWEX 改动肯定就比OLC 大很多了, 并且并不是所有的数据结构都能改成ROWEX, 因为需要保证读操作读取到老的版本程序的正确性.
那么ROWEX 如何解决工程上提到的page 修改non-atomic 的问题呢?
通过Node replacement 的方法, 具体 ROWEX Node replacement 的流程如下:
- Both the node and its parent are locked.
- A new node of the appropriate type is created and initialized by copying over all entries from the old node.
- The location within the parent pointing to the old node is changed to the new node using an atomic store.
- The old node is unlocked and marked as obsolete. The parent node is unlocked.
这里最大的区别是写入的时候将node 拷贝出来, 然后在新的node 上进行改动, parent node 指向 old node 和new node 的指针通过atomic cas (这里保证了修改content 是atomic) 进行切换即可. 然后old node 被标记成unlocked and obsolete.
与OLC 区别在于, OLC 一个Page 只有一个版本, 因此所有的请求都访问该版本. 而ROWEX 有多个版本, 在修改new page 过程中, 老的请求继续访问old page, 等这次修改完成以后, 把new page cas 到parent node 之下,替换old page. 之后再进来的新请求就可以访问new page 了.
最后等这些老的请求都结束了以后, old node 才会被真的物理删除.
那么我们能直接将ROWEX 用于InnoDB 中么?
也很难, 因为这里每一次修改都需要copy node, 开销还是非常大.
Bw-tree
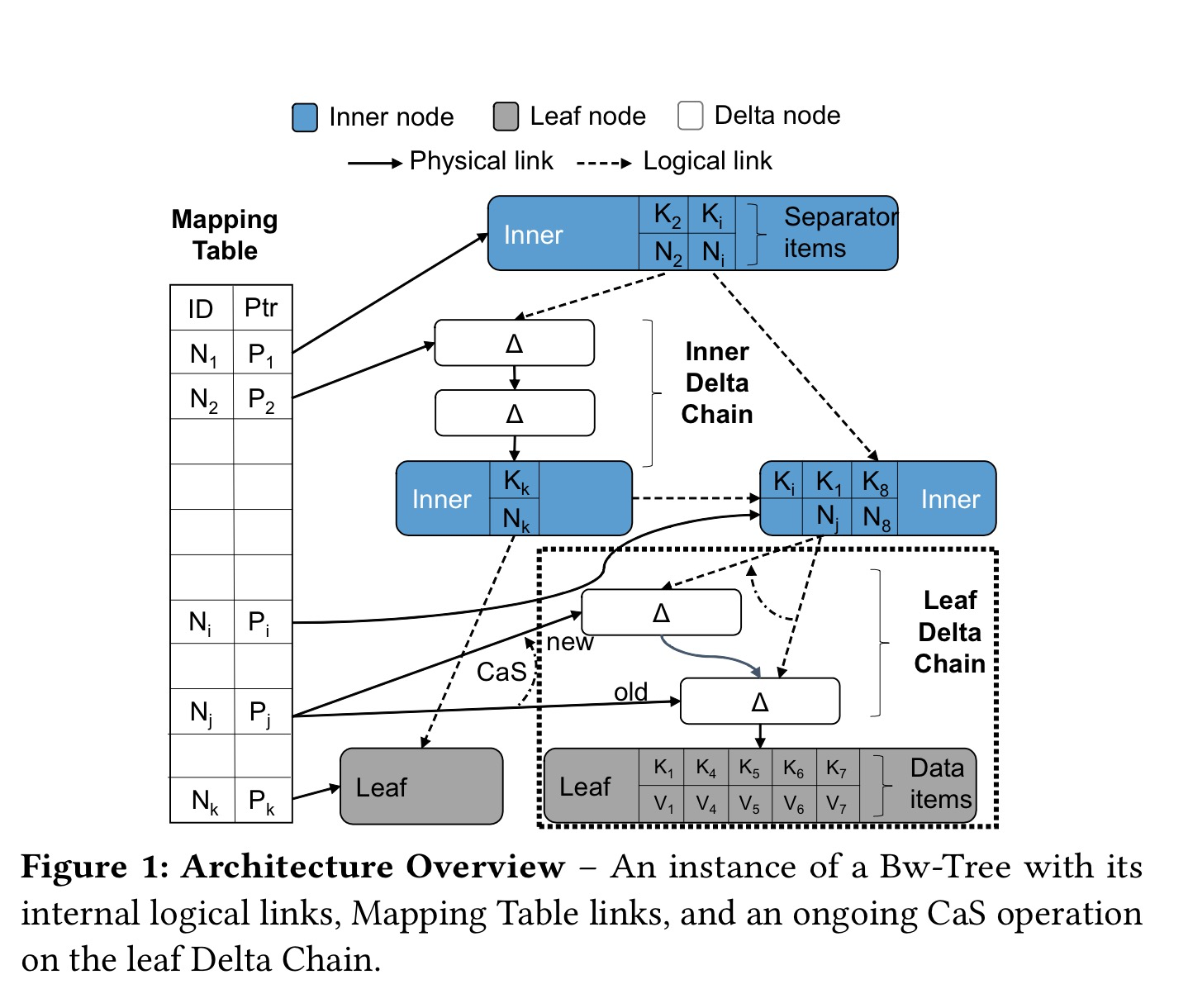
bw-tree 做法整体而言是page 多版本, 多个版本通过delta-chain 连接到一起, 由于page 存在的多个版本, 每次读取操作访问的是不同版本Page, 那么自然就需要引入了mapping table. 所以可以说 delta-chain + mapping table 实现无锁化.
对比ROWEX, ROWEX 将node replacement 的方法常态化, 但是对于page 中每一行的修改都使用copy node 的做法对内存的开销太大, 工程中很难采用.
具体做法是将修改的内容append 到page delta-chain, 然后通过cas 的方式原子的添加到page 的deltai-chain 中, 从而老版本page 不会被修改, 那么读操作自然就可以不需要加锁. 由于读操作不需要加锁, 那么自然就不存在读写冲突. 同样由于读操作不需要加锁, 那么”读读” 操作自然也就不会有冲突.
在之前的 OLC/ROWEX 实现中, 依然还是对page 进行加锁操作, 因此 write-write 还是冲突的, 而在 bw-tree 通过引入delta-chain, 改动都是追加到page delta-chain 中, 因此不同的写入操作可以也可以通过cas 的操作顺序添加到delta-chain, 从而也可以将这些操作无锁化, 所以保证write-write 操作也是无冲突的.
其实可以看到这里对于避免inplace update 的做法, 只有ROWEX 和 bw-tree 这两种做法了.
- 每做一次修改都copy node, 然后进行修改, 然后再进行cas 回去. => ROWEX
- 通过delta-chain 的方式连接到之前的node, 然后再进行cas 回去. => bw-tree
bw-tree 具体实现, 主要两个主要流程:
-
正常的数据append 过程
在append page 过程, 增加delta chain 的过程, mapping table 里面page id => memory 中parse buffer 地址
当比如超过16个, 进行一次consolidate 以后, 但是该page 并没有进行smo, 那么我们的做法是尽可能不去修改Parent node, 那么会纯生存new page, 该page 同样和Delta chain 连在一起. 就变成这样的结构
page id => new page -> delta1 -> delta2 -> delta3 -> oldpage
这里new page = delt1 + delt2 + delta3 + oldpage 的内容.
如果进行consolidate 需要发生smo 操作, 那么就不得不修改parent node, 这个时候会给page 增加一个split deltas, 然后合适的实际进行SMO 操作
-
smo 过程
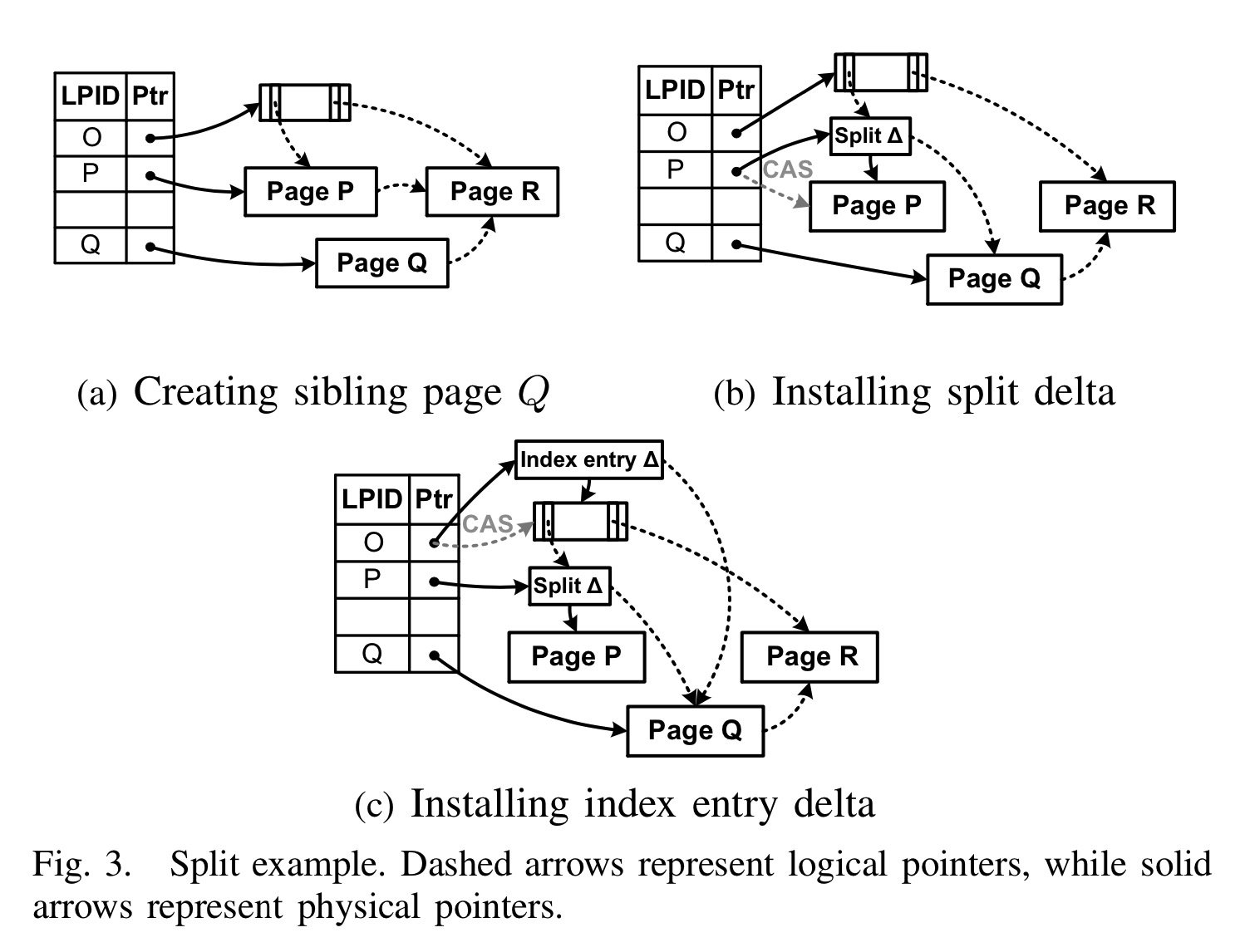
bw-tree 的smo 流程是这样, 整体而言和blink-tree 类似, 分成了2个阶段. 上图的 a + b 是阶段1(处理子节点), c 是阶段2(添加到父节点).
图a 需要计算出seperate key Kp, 增加Page Q, 然后将Page P 上面 >=Kp 的keys 拷贝到Page Q, Q 指向Page R.
注意: 图a 阶段就已经确定了 seperate key Kp
图b 需要增加split delta, 包含
- 增加seperate key Kp, 用来记录哪些record 迁移到Q上
- 增加logic point 指向Page Q.
最后通过CAS 操作, 将Page P 指向split delta.
阶段1 只处理了child node, 并没有把新增加的Page Q添加的Parent node O 上, 和Blink-tree 类似, 访问的时候有可能一半的内容已经迁移到Page Q 了, 但Page O 上面记录的范围还在Page P里面, (因此Page P 需要有一个信息, 这个信息可以记录在Split delta 记录中), 所以和Blink tree 类似, 先访问Page P, 知道Page P 处在SMO 状态中, 然后通过Page P 的link page 到 Page Q.
和Blink-tree 类似, 阶段1 和 阶段2 之前不需要在同一个mtr 里面完成, 到阶段1 完成以后, 是一个合法的Btree. 只不过查询的时候需要额外多走一个Page.
阶段2 做的事情就是把Page Q 添加到父节点Page O 中.
这里Index entry delta 做3个事情
- Page O 需要增加一个seperate key, 访问从[P, R] 变成[P, Q] + [Q, R] 两个, Page Q 负责[Q, R] 的区间
- Page O 需要增加一个point 指向Page Q
- Page Q 和 Page R 的seperate key(其实可以复用Page P 和 Page R, 这个可以忽略)
最后通过CAS 操作, 将Page O 指向这个Index entry delta.
我们来看看这个时候有Read 操作如何保证正确性, 在图a 中时候, 只是增加了Page Q 对任何操作都是不可见的, 因此没有问题.
图b 增加了Split delta, Page P + Delta 是最新版本, 这是一次cas 操作, 完成以后P ->next = Q. Q->next = R(图a中修改), 那么此时的访问依然没有正确性问题.
如果此刻有一个mtr 访问的是Old Page P(不包含Delta), 然后访问next page, 依然是正确的.
图c 同样通过一个cas 操作将Page Q 添加到Page O中, 依然没有正确性问题.
如果这里Page P 已经把一半的内容迁移到Page Q 了, 那么这个时候Page P 还有写入, 这个时候该如何处理?
也就是SMO 和正常写入的冲突, 以及SMO 和SMO 的冲突.
bw-tree 文章在 C. Serializing Structure Modifications and Updates 讲的过程
文章里面说的是, 对于同一个row 的修改, 通过事务锁去保证. 目前InnoDB 也是这么做的. 在lock 模块就已经冲突了, 就不可能拿到page latch.
这里需要处理SMO 和 SMO 的关系, 以及SMO 和正常写入的关系.
因为bw-tree 是无锁的. 所以SMO 过程中(阶段1 和 阶段2中间) 比如会穿插正常的查询和写入操作, 甚至SMO 操作.
bw-tree 选择的操作是, 如果候选的查询或者写入遇到了处在smo 中间状态的节点, 那么该操作会帮助完成这次smo 操作.
原因是如果Page P 正在做SMO 期间, 又有写入操作, 假设写入的内容应该写入到迁移完成的Page Q上, 因为SMO 操作还未完成, 也就是已经完成了图a, 确定了seperate Key Kp, 这个时候其实应该把新的内容写入到Page Q 的delta chain 上, 但是此时该操作是不知道的.
因此bw-tree 选择的是Page P 上标记正在进行smo 的状态, 那么写入操作帮忙Page P 完成这次SMO, 然后等SMO 结束以后已经知道Page Q了, 再把要写入的内容写入到Page Q上.
bw-tree 为了解决write SMO 的时候同时有新的write 进来的时候, Bw-tree 让新的write 完成前面write SMO 操作, 但是具体工程实现上, 这样的操作想想就过于复杂, InnoDB 的btree 需要同时承担事务锁相关能力, 更增加了复杂度.
结论
笔者主要站在工业界的视角看学术界如何解决btree 在multi-core 场景下的性能问题, 了解这些学术界的实现, 看是否对工业界有帮助.
目前看来, 学术界这些新型的数据结构在工程上落地都有一定的难度.
比如OLFIT假设读取一个page 是atomic 的, 这个在工程上是无法实现的. 也就是读取的时候如果有写入, 虽然后面可以通过版本号判断是旧的,但是可能存在的问题是读取了一半的内容, 那么使用这一半内容的MySQL程序本身就会corrupt.
比如ART Tree 通过copy node 的方式实现Atomic 修改, 但是这样拷贝的开销工程上是无法接受的.
比如Bw-tree 处理SMO 的时候如果有write 操作, SMO 和 SMO 的冲突的解决方案过于复杂等等.
有些方案是latch-based, 有些方案是latch-free, 有些是hybrid, 在工程上我们一般如何考虑呢?
在文章 “Latch-free Synchronization in Database Systems: Silver Bullet or Fool’s Gold?” 给出了比较有意义的结论:
Latch free Algorithm 通常在线程数超过CPU 核数的场景下, 比 latch-based 的算法要来的好.
In this traditional database system architecture, the progress guarantees of latch-free algorithms are extremely valuable because a preempted context will never block or delay the execution of other contexts in the system (Section 2).
因为在latch-based 做法里面, 当核数比thread 数多的时候, 有可能当前持有latch 的thread 被CPU 调度出去, 而其他线程被调度执行, 但是因为在等锁, 也无法执行, 持有latch 的thread 又得不到cpu, 陷入了死锁.
在这种场景里面. latch free 算法有优势, 因为latch free 并没有一个thread 持有latch, 所有thread 都尝试乐观获得old value, 然后尝试更新, 最后再commit, 如果commit 之前被cpu 调度出去, 那么切回来以后可能old value 已经被修改了, 仅仅是commit 失败而已, 不会影响其他thread. 所以cpu 的调度对latch free的影响是不大的.
当然这里的本质原因是操作系统的调度不感知用户层的信息, 也不可能感知. 持有Latch thread 和waiting latch thread 在操作系统眼里是一样的.
现在一些新的im-memory database 一般采取latch based 的方法, 尽可能不依赖操作系统的调度.
而MySQL 正好属于这种场景, 在大量的并发场景下, 活跃连接远远高于cpu 核数. 所以latch free 是有意义的.
但是现在新的Database 比如in-memory database 都是和core 绑定, 比如redis 这种单线程的. 包括polarstore 也是这样的设计, 那么这种场景下, 由于冲突不明显, 本身设计就考虑了尽可能减少contention, 所以latch-based 就更好了. 因为latch-based 更简单, lock-free 需要一些复杂的内存管理解决 ABA, garbage collect 等等问题.
所以作者不建议database 里面建议使用latch-free algorithm, 更建议好好优化Latch-based algorithm.
最后强调multi-core 上的scalability 重点在于减少在single shared meomry 上面的频繁操作, 也就是contention. 而不是在于选择latch-free 和 latch-based 的算法. 其实这个观点也是能理解的, 本质是能通过业务逻辑的设计避免contention 肯定是最好的.
但是MySQL 内部其实有一些逻辑避免不了contention, 比如lock_sys->mutex, trx_sys->mutx 等等.
另外可以看到实现一个bw-tree, blink-tree 在学术界的论文里面是非常简单的一个事情, 但是InnoDB 里面Page 里面结合了事务锁, 并发控制, undo log 等等一系列内容, 所以将InnoDB 的btree 修改并稳定到线上其实是比较大工程量的事情, 比如为了推动Blink-tree 上线, 笔者就写了Inno_space 这样的工具, 用于如果真的有数据损坏的情况, 对数据进行修复, 为了前期的灰度, blink-tree 先上线到二级索引等等这样的工作.
那么PolarDB 是如何处理这个问题呢?
References:
[1] Z. Wang, et al., Building A Bw-Tree Takes More Than Just Buzz Words, in SIGMOD, 2018
[2] S.K. Cha, et al., Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems, in VLDB, 2001 (Optional)
[3] G. Graefe, A Survey of B-Tree Locking Techniques, in TODS, 2010 (Optional)
[4] J. Faleiro, et al., Latch-free Synchronization in Database Systems: Silver Bullet or Fool’s Gold?, in CIDR, 2017 (Optional)
[5] J. Levandoski, et al., The Bw-Tree: A B-tree for New Hardware, in ICDE, 2013 (Optional)
[6] V. Leis, et al., The ART of Practical Synchronization, in DaMoN, 2016 (Optional)
[7] V. Leis, et al., The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases, in ICDE, 2013 (Optional)
[8] https://15721.courses.cs.cmu.edu/spring2020/schedule.html
[9] https://zhuanlan.zhihu.com/p/374000358