AWS re:Invent2022 Aurora 发布了啥
AWS reInvent 2022正在进行中, 笔者作为数据库从业人员主要关注的是AWS Aurora 今年做了哪些改动.
前面照例是每年都有的Aurora 整体架构介绍.
在基础能力方面:
- Aurora 做到了一个aurora 集群上实例的不同规格, 甚至可以是x86和 arm 的混部集群
- Aurora 封装了jdbc driver, 这样在client 就能够针对Aurora 的rw, ro 做不同的心跳检测等等. 实现快速的failover
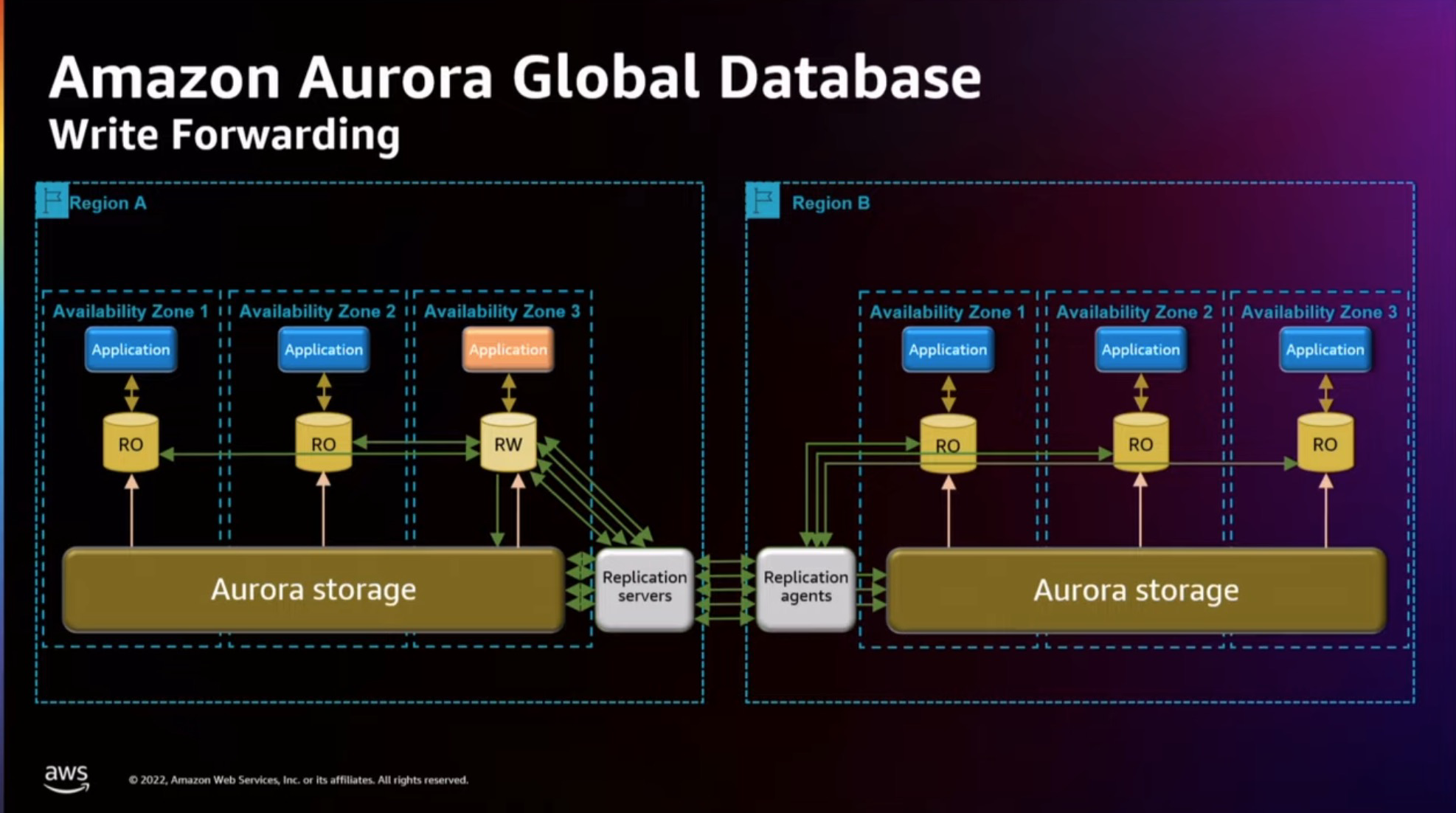
在Aurora Global Database 方面
-
Aurora GDN 推出了计划内切主(命令叫failover global cluster command). 计划内切主完会重新建立主备关系, 包括Replication Server 和 Replication Agent. 计划外切主完以后, 不会主动切回去
这个能力PolarDB 一直都有, 今年PolarDB GDN 也增加了计划外切主的能力
-
Aurora GDN 不同的region 可以是serverless 的, 不同Region 的实例规格也可以完全不一样.
-
aurora 路由写的参数叫 enable-global-write-forwarding. aurora 这里提供了两种一致性1. secondary region 写入一定能读到 2. 写入最终能读到
如果你的application 是大规模的读, 然后小规模的写, 那么Aurora Global Database 这个架构非常合适你的业务
在存储能力方面:
-
存储重点提了 fast clone 的能力, 其实这个能力polarstore 也有了, 就是快照可写, 你不需要付费知道你对这个快照写入了一些东西
虽然这里讲了快照对原有实例是毫无影响的, 但是其实在IO 压力大的时候, 还是会互相影响我理解.
-
有一个parallel export 的能力把aurora 里面的内容dump 到s3. 可以通过fast clone 的能力clone 出一个实例, 然后在执行
-
Aurora 也发布了一个logical redo Log 能力, 叫Enhanced binlog. 文章后面会重点介绍
在Serverless 方面
- buffer pool resizing, aurora serverless 强调不仅仅是cpu serverless 而且 memory serverless 也很重要
Enhanced Binlog

这里重点介绍一下我觉得对客户很有帮助的Enhanced binlog, PolarDB 也在解决类似的问题, 是通过Logical redo log 的方法.
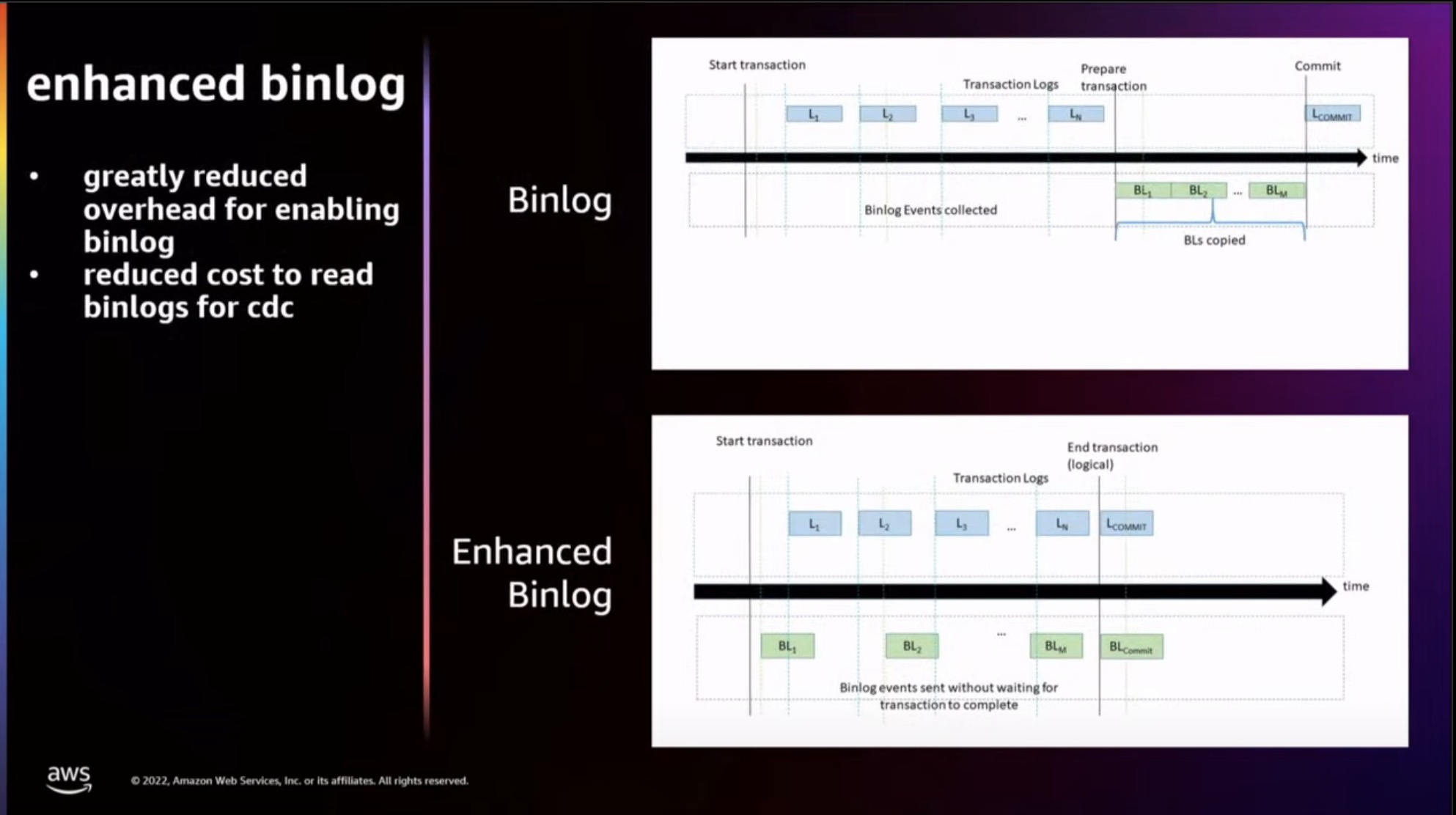
在Aurora 上面开启binlog 以后会造成性能退化, 极端情况有80% 的性能损失, 正常情况下也有50% 左右, 因为需要增加了一个额外的binlog IO. 而我们之前在CloudJump 文章也提到过在云存储上面IO 比本地盘慢很多. Enhanced binlog 就是要解决这样的问题.
enhanced Binlog 原理
在事务开始后, MySQL 会将持续产生的 binlog events 写入事务自己的 cache, 如果超过了阈值, 那么就写入到 tmpfile 中,
在事务提交时,将自己积攒的 binlog events 顺序写入到 binlog 文件,并做一次 sync。group commit 优化也只是把多个事务 binlog 刷盘 IO聚合。
可以看到 commit 时候,从 cache/tmpfile 拷贝数据到 binlog 文件(计算节点->存储节点),这个过程是比较耗时的. 在计存分离的架构下, 这个延迟问题更加明显.
举个极端例子,一个 100G 大事务,提交时要持锁写入 binlog 文件(polardb目前大概十分钟),同时阻塞其它事务提交。
enhanced Binlog 的 在事务进行中,将已经产生的 binlog events 不再缓存在计算节点,而是直接发给存储,存储来进行感知并缓存。
而提交时,存储有能力将指定事务缓存的 binlog 内容快速链接到 binlog 文件后面,只需要一个 link 操作,这是远快于将全部数据从计算节点 copy 到存储节点.
我理解这个优化的核心是在进行大IO 的过程中, DB提前将IO 发送给存储, 存储可以cache 或者暂存, 那么等真正提交的时候, 就不需要再进行数据同步, 而是同步提交信息就可以. 我理解这个也是计存分离架构下, 对大IO 优化的一种思路.
PolarDB 采用的思路是logical redo log, 通过将redo log IO 和binlog IO 合并成一次进行优化, 具体可以看这个介绍
https://zhuanlan.zhihu.com/p/582575542
BTW:
作为数据库行业的从业人员看来, Aurora 定义为云原生数据库, 这几年Aurora 很大的发力点都在”云原生”上, 比如serverless, Blue/Green Deployment 等等, 但是在”数据库”这个关键字上并没有做很多事情, 更多的是从upstream 更新了, 毕竟数据库内核这个事情创新起来更难了.