PolarDB auto_inc 场景性能优化之路
在数据库的使用场景中, 最常见的场景是并发插入或者导入数据场景, 在该场景中并不指定自增id, 由数据库自动生成自增id, 然后插入到数据库中, 因此我们也叫auto_inc 场景的数据插入.
典型的业务场景如: 游戏行业开服过程中的大批的登录注册场景, 电商活动中给商家后台推单场景等等.
我们看看PolarDB 是如何优化针对这种并发插入场景进行优化的.
背景知识:
在这种并发插入场景中, 自增id 是递增的, 因此插入的时候其实是插入到btree 最右边的Page 中去的.
直观感受上这种场景是插入到btree 最右一个page, 真的是这样么?
**其实不是, 这种场景并不能保证插入数据是连续的, 因此有可能要插入的值比最右Page 最小值小, 插入右边第2个page. 因此这种场景其实是插入最右的多个page. **
原因是thread 获得auto_inc 值以后, 到真正进行insert 这一段代码并没有加锁, 因此thread 获得auto_inc 以后被调度走, 反而后面获得auto_inc thread 先进行最后的insert 操作.
所以这样的场景是允许出现的: 并发Insert 时, 后续有可能插入比当前 auto_inc value 小的行
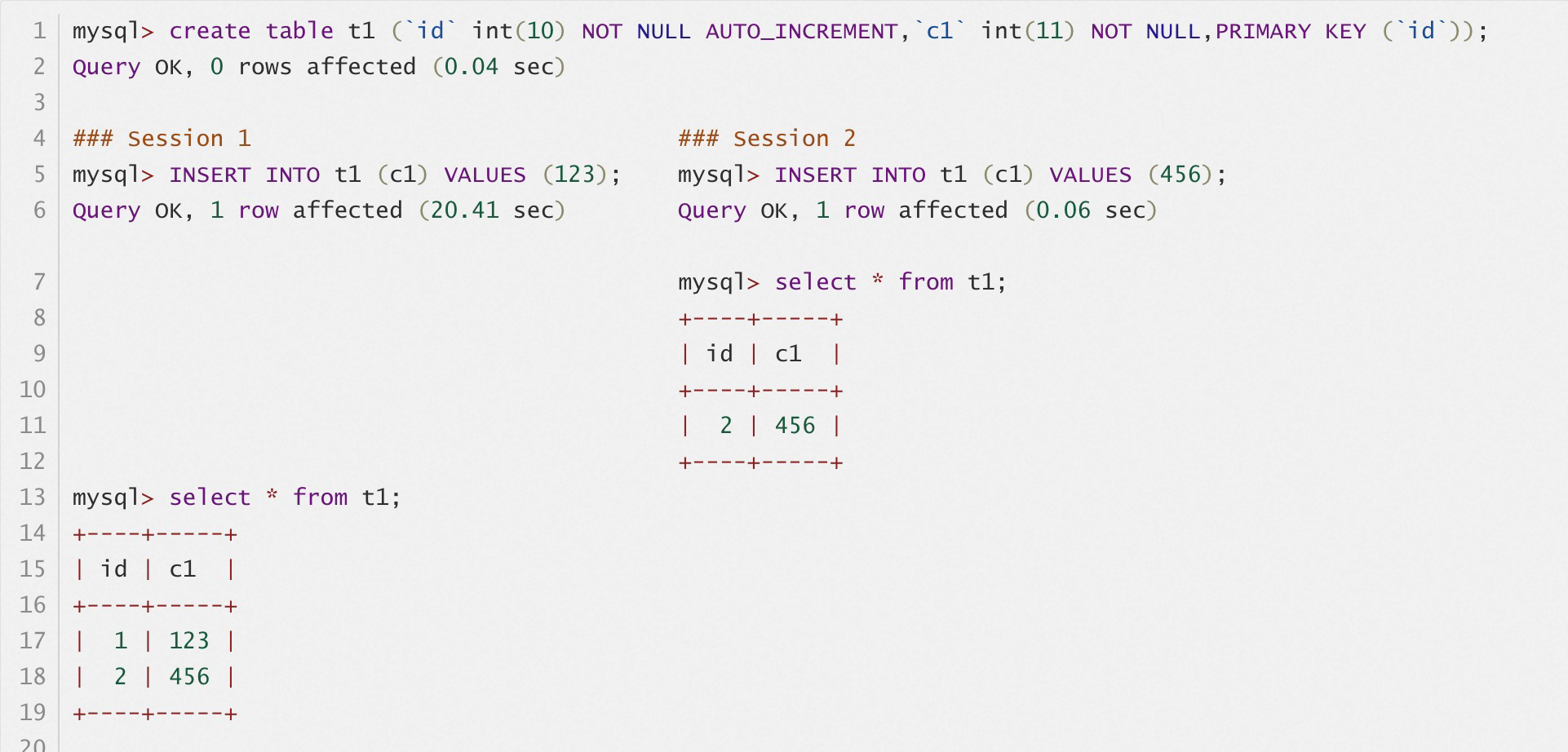
因为这个原因允许Level 0 存在多个page 同时进行插入情况, 允许我们有性能优化的空间. 否则仅仅插入最右page, 就相当于排队对最右Page 进行插入, 没有优化空间.
因此会出现以下场景
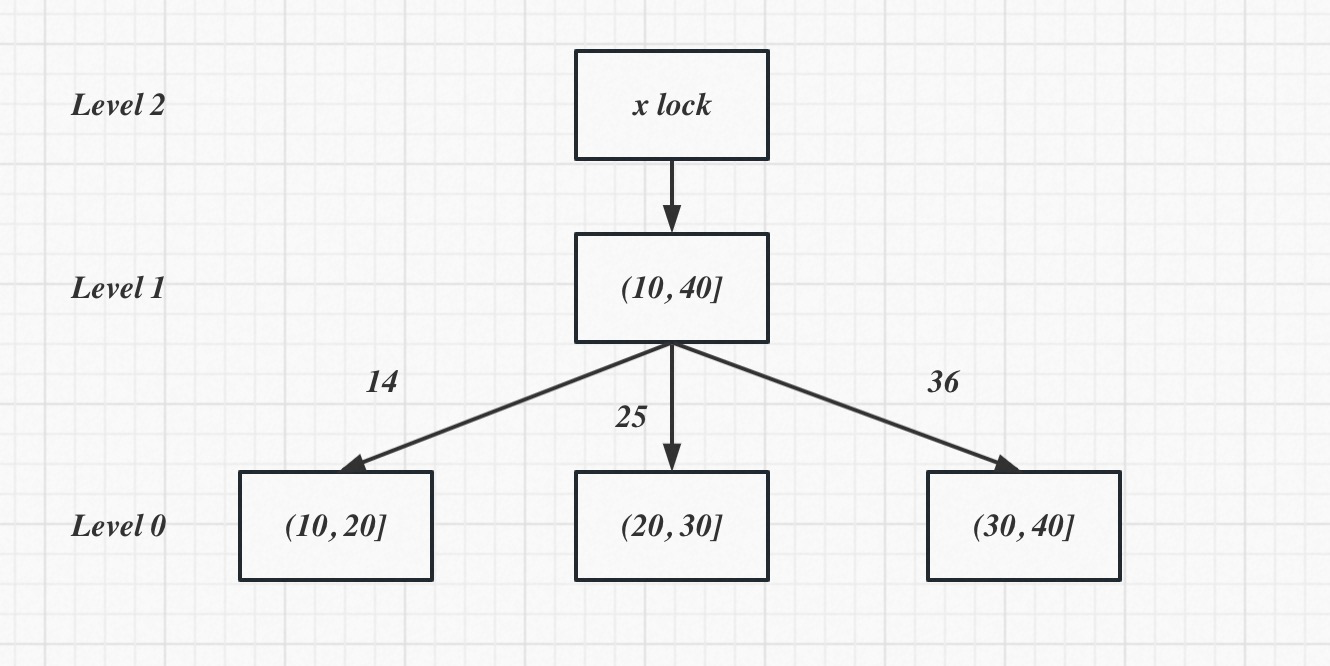
在上图中, 此时有3个thread 进行乐观插入, 插入的value 14, 25, 36. 那么此时可以持有各自page x lock, 实现3 个page 同时并发插入.
如果thread = 1, 那么只有最右page 进行插入, 性能一定是不如3个page 同时并发插入来得好.
理论上允许同时插入的leaf page 越多, 并发越高, 性能越好.
那么如果实现允许同时插入的leaf page 越多呢?
尽早进行SMO 操作, 最右Page 尽早分裂, 那么就有更多未被插满的Page 允许用户同时进行插入
所以接下来我们的优化点就是
尽早进行SMO 操作
尽早进行SMO 操作
尽早进行SMO 操作
那么在并发插入场景中, InnoDB 中实际情况是怎样的?
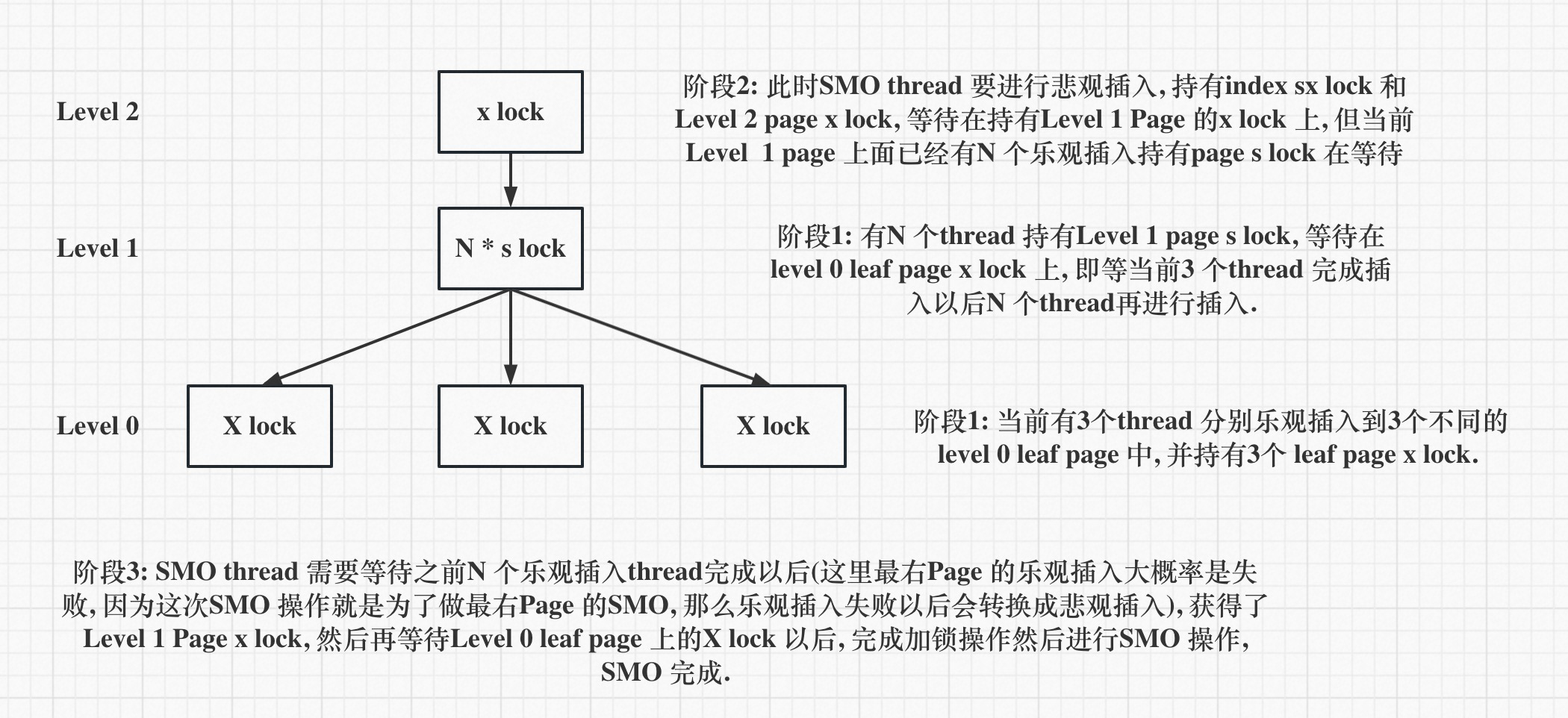
在我们测试中, 发现可能存在因为调度问题造成auto_inc 差值差不多能够造成同时3~4 个page 允许同时插入, 上图也是这样的初始场景.
阶段1: 当前有3个thread 分别乐观插入到3个不同的level 0 leaf page 中, 并持有3个 leaf page x lock. 同时还有N 个thread 持有Level 1 page s lock, 等待在level 0 leaf page x lock 上, 即等当前3 个thread 完成插入以后N 个thread再进行插入.
阶段2: 此时SMO thread 要进行悲观插入, 持有index sx lock 和 Level 2 page x lock, 等待在持有Level 1 Page 的x lock 上, 但当前Level 1 page 上面已经有N 个乐观插入持有page s lock 在等待
阶段3: SMO thread 需要等待之前N 个乐观插入thread完成以后(这里最右Page 的乐观插入大概率是失败, 因为这次SMO 操作就是为了做最右Page 的SMO, 那么乐观插入失败以后会转换成悲观插入), 获得了Level 1 Page x lock, 然后再等待Level 0 leaf page 上的X lock 以后, 完成加锁操作然后进行SMO 操作, SMO 完成.
这里可以看到SMO thread 需要等待N 个Thread 完成乐观插入尝试以后, 才可以进行SMO 操作, 并发度越高, 乐观插入thread 越多, 那么SMO thread 等待的时间越长, SMO 越不能尽早执行, 导致性能无法提升.
那么为什么限制了Innodb_thread_concurrency 以后, 可以获得更好的性能呢?
从上面的分析可以看到, 其实在auto_inc 场景, 允许并发插入的page 并不多, 差不多只有3~4 个page 允许同时插入, 过多的线程会导致SMO 线程必须等这些乐观插入线程插入尝试完成以后才能进行插入, 乐观插入thread 越多, 等待的时间越长. 最理想的情况是此时最右Page 上没有乐观插入在等待, 那么SMO thread 可以不需要等待任何thread, 实现了尽早进行SMO 操作 这个目标. 而限制了Innodb_thread_concurrency 相当于限制了这里乐观插入thread 数目, 因此实现了更好的性能.
实际测试中Innodb_thread_concurrency = 8 就可以几乎最好的性能了.
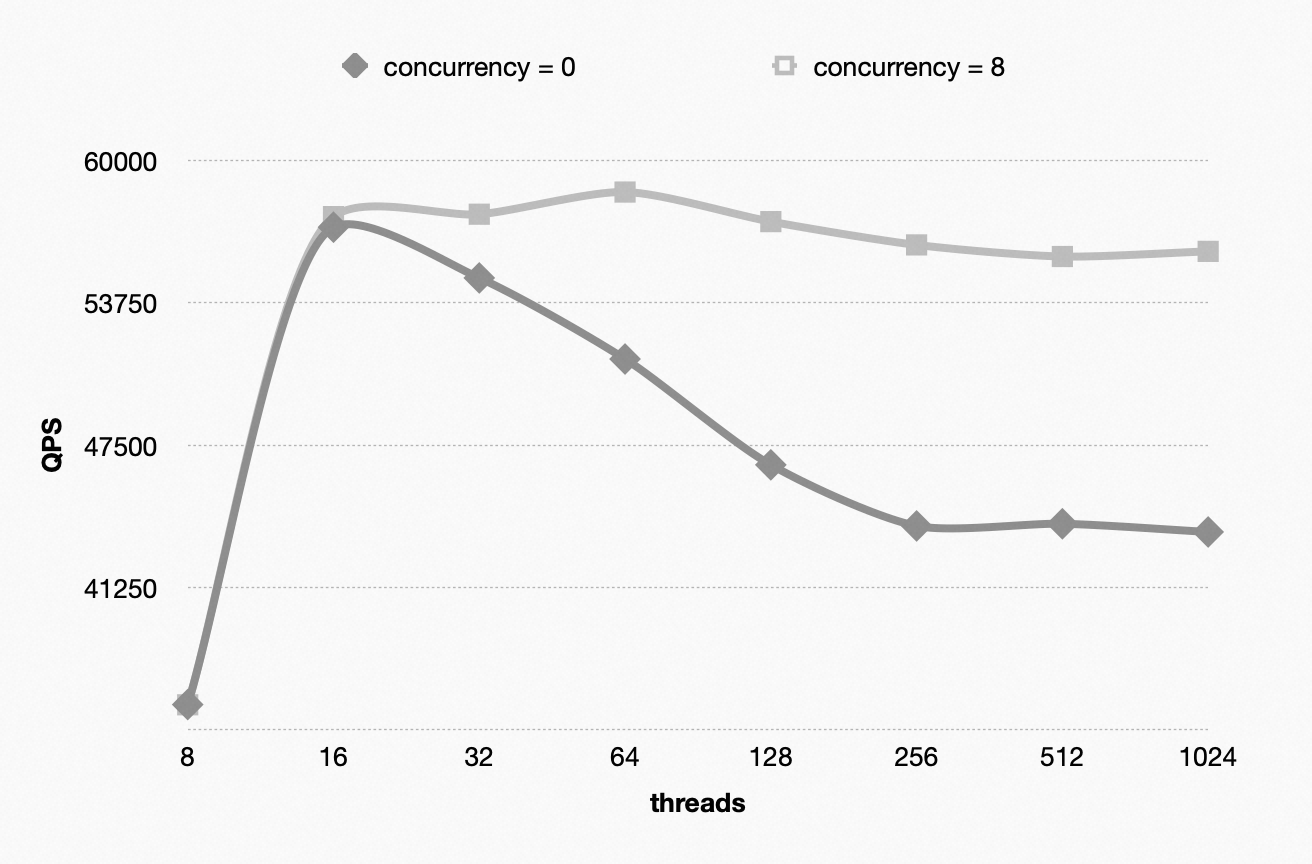
那么Blink-tree 如何改进这种情况呢?
我们分析现有InnoDB Btree 版本存在的问题的时候提出解决方案通过设置 Innodb_thread_concurrency = 8 来降低并发进入到InnoDB thread num 从而保证高性能的插入, 但是Innodb_thread_concurrency = 8 太低, 正常系统使用的过程中还有查询操作, 因此实际上很少会进行这样的设置, 那么Blink-tree 最后是如何实现允许大量并发线程并能够实现高性能auto_inc 插入呢?
-
Blink-tree 天然允许SMO 并发, 现有InnoDB Btree 同一时刻只能允许一个SMO 进行, 允许了SMO 并发执行相当于尽早进行SMO 操作
-
增加了SMO thread 还不够, 如果SMO thread 和上述InnoDB btree 实现一样, 需要等待乐观插入完成才能进行SMO 操作, 那么其实多个SMO 操作也是串行的, 仅仅增加一点提前执行SMO 的时间.
因此我们在Blink-tree 上实现锁的优先级调度, 从而实现尽早进行SMO 操作.
在上述阶段3 中SMO thread 需要和乐观插入thread 去争抢执行优先级, 导致SMO thread 执行效率不高. 通过锁的优先级调度, 给SMO thread 最高优先级, 先唤醒等待在Page x lock 上的SMO thread, 然后再唤醒等待在address lock 上的乐观insert thread, 从而实现尽早进行SMO 操作
具体实现方式如下图所示:
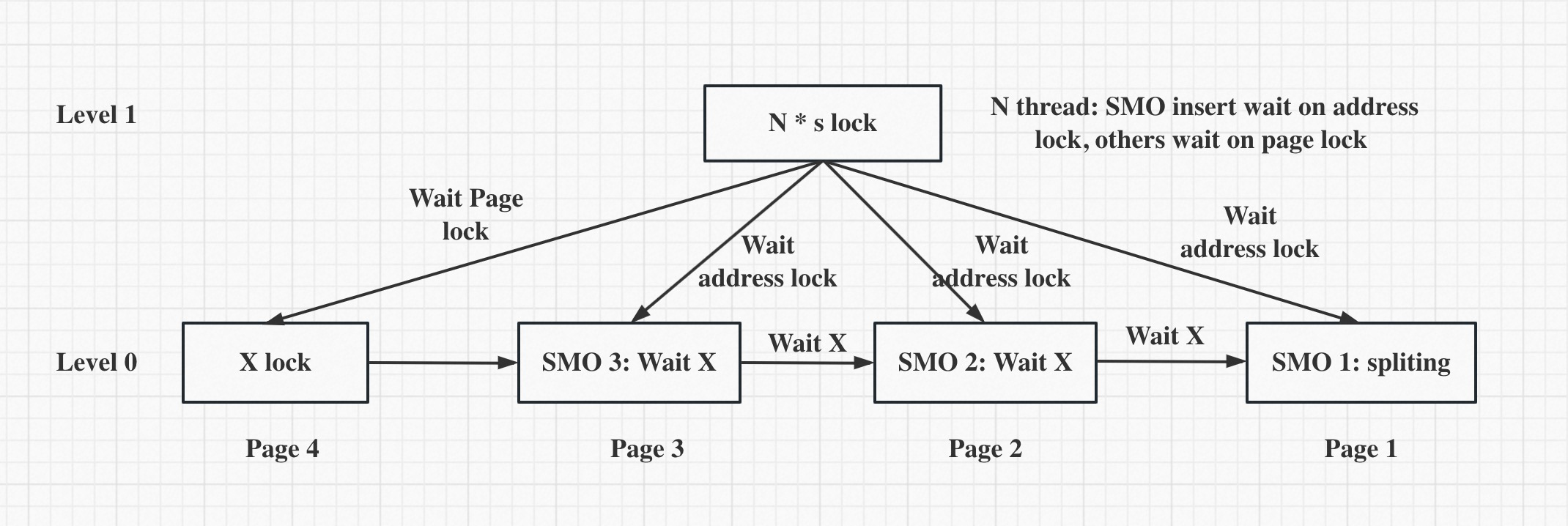
Blink-tree 通过Lock coupling 进行加锁, 即使在悲观插入场景中, 对Level 1 依然是 S lock.
阶段1: 当前有3个SMO thread 正在并发进行SMO. 因为Blink-tree 实现SMO 和Btree 类似, 需要持有中右page lock, 因此只有SMO 1 能够执行, 而SMO 2/SMO 3 等待在右Page Xlock 上.
阶段2: 有N thread 尝试进行乐观插入操作, 乐观插入的时候发现Page 1/2/3 都在进行SMO 操作, 只有Page 4 没有, 因此想插入Page 1/2/3 threads 放弃当前Page s lock, 等待在Page 1/2/3 的address lock 上. 想插入Page 4 thread 等在Page 4 x lock 上.
阶段3: SMO 1 执行完成SMO, 通知SMO 2 进行, 然后唤醒等待在Page 1 address lock 上的乐观插入thread, 由于SMO 2 还在进行中, 持有Page 1 X lock, 因此乐观插入thread 需要等SMO 2执行结束才可以执行. 等SMO 2执行结束通知SMO 3执行, 同时唤醒等待在Page 2 address lock 上的乐观插入, 但是由于SMO 3正在进行中, 持有Page 2 X lock, 因此乐观插入Page 2 因为SMO 3 持有Page 2 X lock, 是无法进行的. 但是此时对Page 1 乐观插入已经可以进行了.最后等SMO 3 也完成, Page 2/3 的乐观插入也就可以进行了
可以看到blink-tree 通过增加并发SMO thread 同时引入锁的优先级调度从而实现尽早进行SMO 操作. 从而实现比InnoDB Btree 更高的性能.
这里其实还有一个与InnoDB Btree 实现的区别, 等待在address 唤醒之后的乐观插入 thread 执行的依然是乐观插入操作, 而InnoDB Btree 在等待Page lock 被唤醒之后执行的是悲观插入操作. 悲观插入加锁的范围广开销大, 因此性能进一步退化.
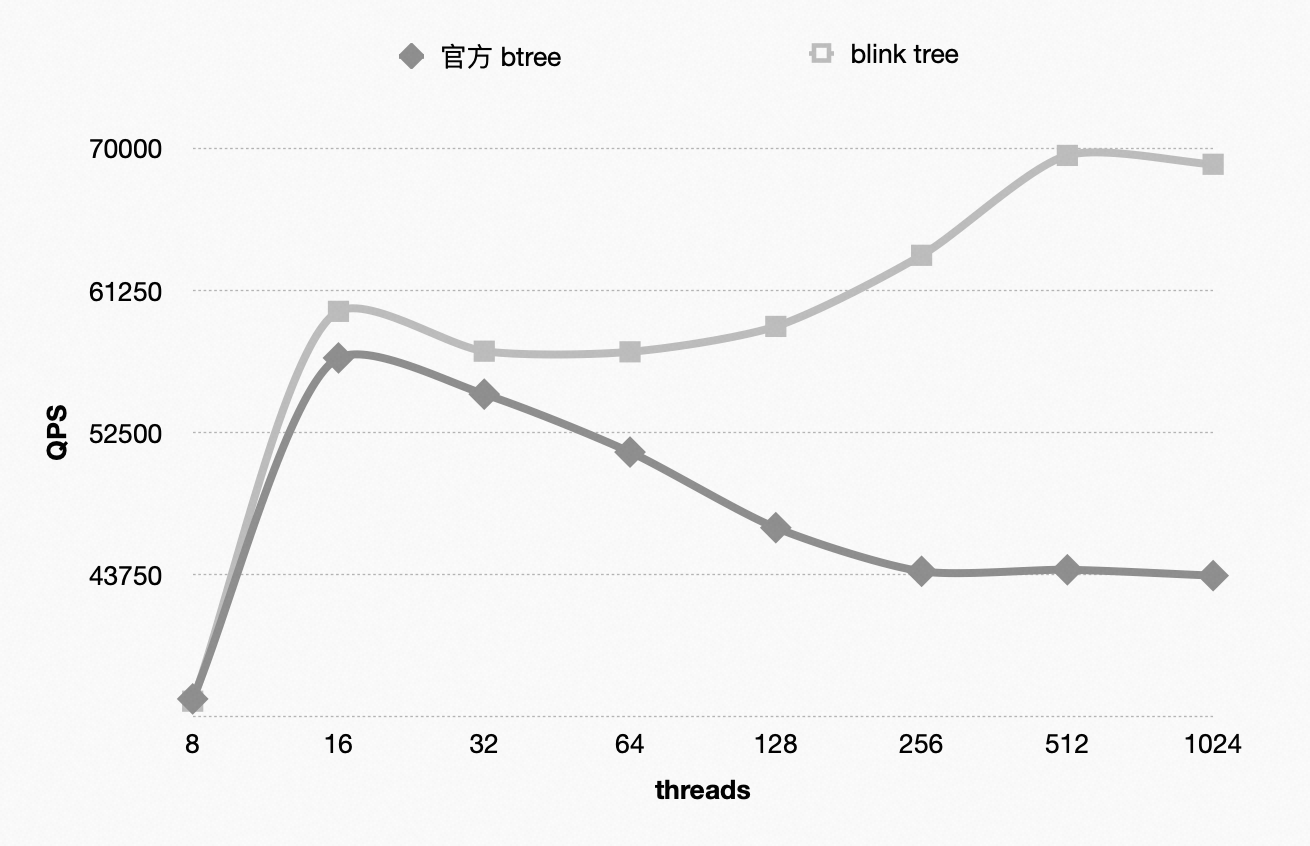
可以看到在Blink-tree 场景中. 在并发场景中, Blink-tree 是官方版本的2倍, 同时比开启Innodb_thread_concurrency 也有13% 左右提升.
具体测试场景的数据如下:
总结:
可以看到在Blink-tree 场景中. 在并发场景中, Blink-tree 是官方Btree版本的2倍, 同时比开启Innodb_thread_concurrency 也有13% 左右提升.
那么Bw-tree 如何改进这种情况呢?
看下一篇文章…