AWS re:Invent2023 Aurora 发布了啥
这个是去年AWS re:Invent 2022 的内容, 有兴趣可以看这个链接: Aurora re:Invent 2022
AWS reInvent 2023 刚刚结束, 笔者作为数据库从业人员主要关注的是AWS Aurora 今年做了哪些改动.
笔者主要介绍 4 个方面感兴趣的内容
- Aurora limitless
- Global Database
- Performance
- 存储计费
Aurora limitless
今年发布会最大的内容应该是推出了Aurora limitless 去解决 Database scaling 的场景, 类似的产品在已经非常多, 像 Spanner/TiDB/OceanBase/Polar-X.
从产品能力上, 支持Shared table 和 Reference table.
从下图可以看到 Shared table 将一个 table partitioned 到多个 Shared 上.
Reference table 将一份数据 Copy 到多个 Shared 中, 每一个 Shared 都有完整的数据, 主要解决的场景是在 Join 等场景中, 可以做到 Local Join 从而优化性能
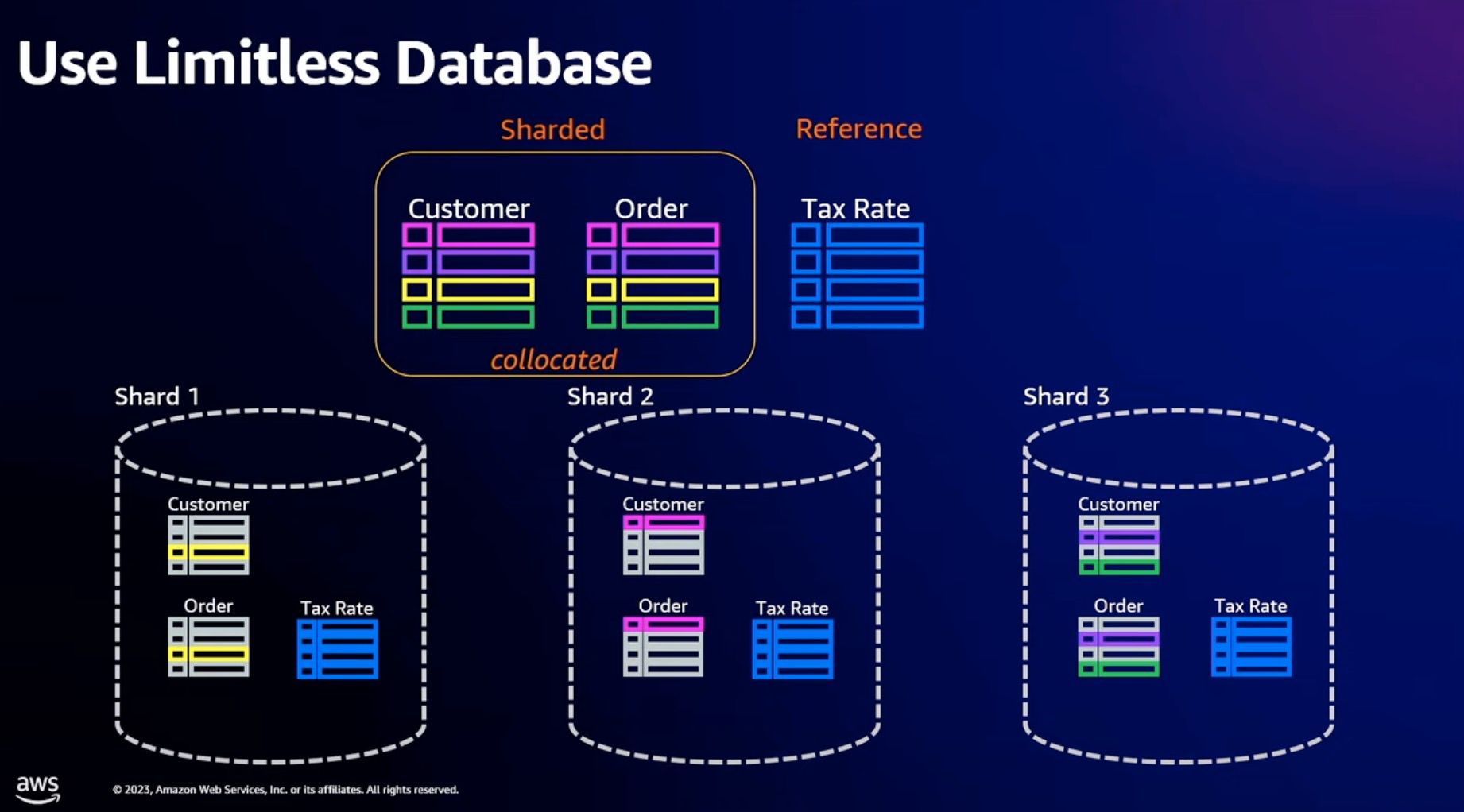
在具体用户使用上, 需要用户手动指定 create_table_mode, create_table_shared_key, create_table_collocate_with 等等语句对用户有感的实现Sharding
# Create Sharded Table
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key='{"cust_id"}';
CREATE TABLE customer (
cust_id INT PRIMARY KEY NOT NULL,
name ТЕХТ,
email VARCHAR (100)
);
SET rds_aurora.limitless_create_table_mode='sharded';
SET rds_aurora.limitless_create_table_shard_key:='{"cust_id"}';
SET rds_aurora.limitless_create_table_collocate_with='customer';
SET rds_aurora.limitless_create_table_mode ='reference';
具体在技术实现上:
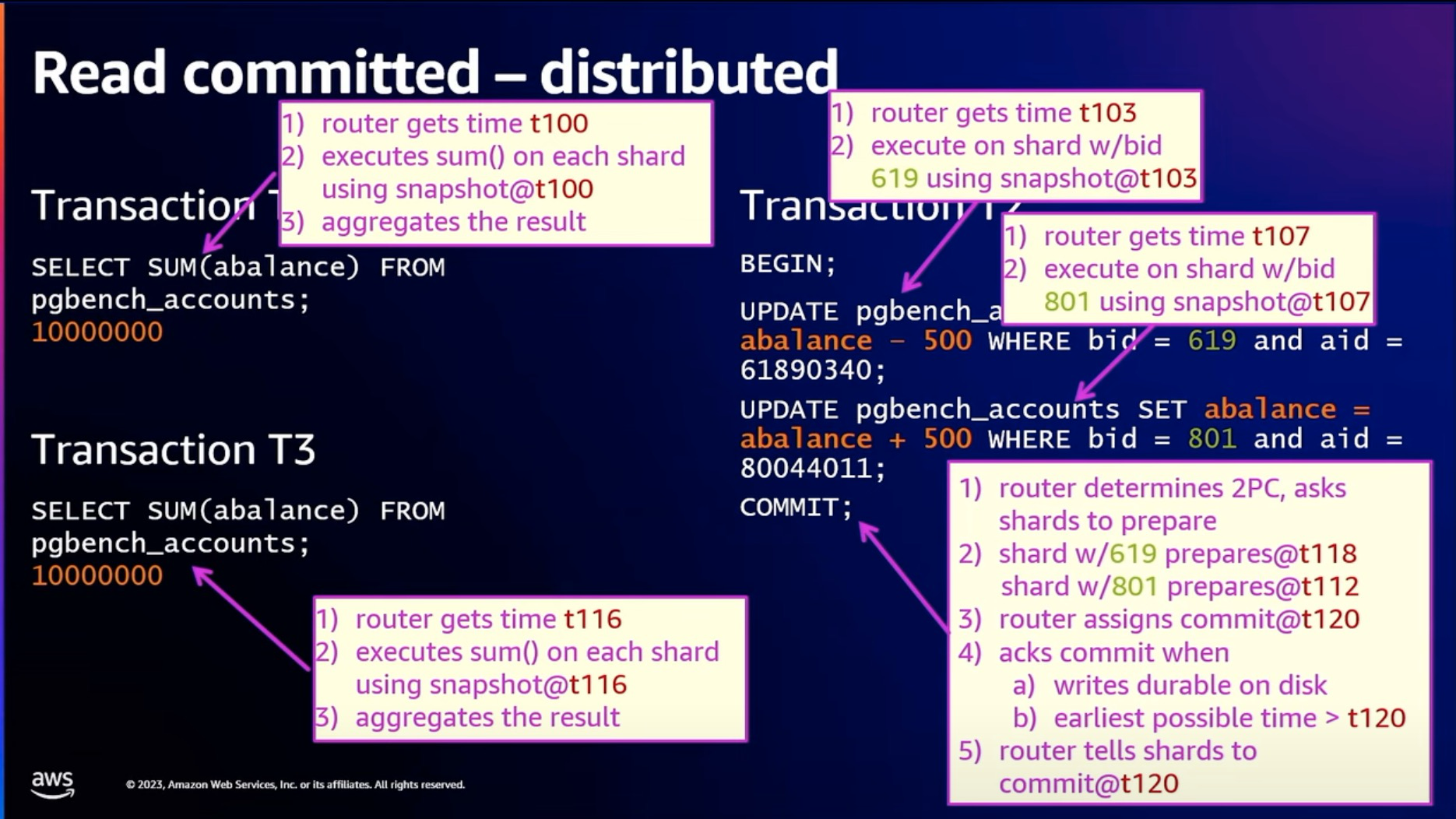
在分布式事务实现上, 通过EC2 TimeSync service 实现和 Google 的 True Time 类似的解决方案.
Ture Time 解决方案核心逻辑是 adding latency in the commit time. 在 Spanner 里面这里叫 commit wait. 等earlist possible time > t110 的时候, 那么就可以确保事务提交了, 这里肯定增加了commit 的时候的 latency, 这里EC2 TimeSync service 越精确, 也就是[earliest possible time, latest possible time] 范围越小, 那么对事务提交的影响是越小的.
这里 Aurora limitless 做了优化, commit wait 的时候和 disk IO 是并行的, 由于在寄存分离架构下, disk IO 是网络的 disk IO 需要增加网络的延迟, 这里一般单次 IO 在 tcp 场景下是有可嫩需要 300~400us 左右的. 而 EC2 TimeSync service 保证的精确时间在 us 级别, 那么绝大部分情况下这个时间都可以忽略不计, 因为大部分commit wait 的过程, disk IO 还没有完成, 所以这里可以忽略不计了.
注意: 这里是在 T2 是在获得 commit@t110 以后, 开始等待的.

笔者观点:
Aurora limitless 定位有点尴尬, 不一定能够发展很好. 目前 Aurora limitless 仅仅支持指定shared_key, 对应的 PolarDB-X 同时支持指定 shared_key 以及对用户完全透明无感的分布式, 以及类似的 tidb 支持对用户完全透明无感分布式.
实际上我们看到对于云上分布式数据库一直又这样尴尬的情况, 小客户数据量和写入量整体不大, 不需要使用分布式数据库, 大部分情况 PolarDB/Aurora 这种 share storage 场景就可以满足, 难得有用户想要使用分布式数据库的要求, 希望的又是完全无感使用, 因为不指定 shared_key 从而性能可能不如单机数据库来的理想. 而 Aurora limitless 的使用方式小客户可能肯定不会使用了
大客户可能存在使用分布式数据库的场景, 也愿意学习使用指定 shared_key 的方式从而实现更好的性能, 但是大客户又会担心被云厂商绑定等等问题, 在分布式数据库还没有成为标准的情况下, 不愿意使用云厂商的分布式数据库, 更多愿意使用开源数据库自建的方式使用数据库.
Global Database
Aurora Global Database 推荐计划内切主的能力, 叫 Switchover. 在 PolarDB 上面的跨 AZ 切换场景中, 主可用区切换是类似的能力.
这个场景里面 Switchover 会等待两个 Region 的 write lsn 完全对齐以后, 再进行切换. 从而保证 RPO = 0. 同时也保证 standby region 的资源和 primary region 对齐, 从而不影响切换过来的性能.
他们的一个 User Case 是. 有一个客户每天进行 3 次跨 region 切换, 因为他们的业务是全球的, 白天时候是高峰期, 所以一直切换保证就近的 Region 读取的性能是最好的.
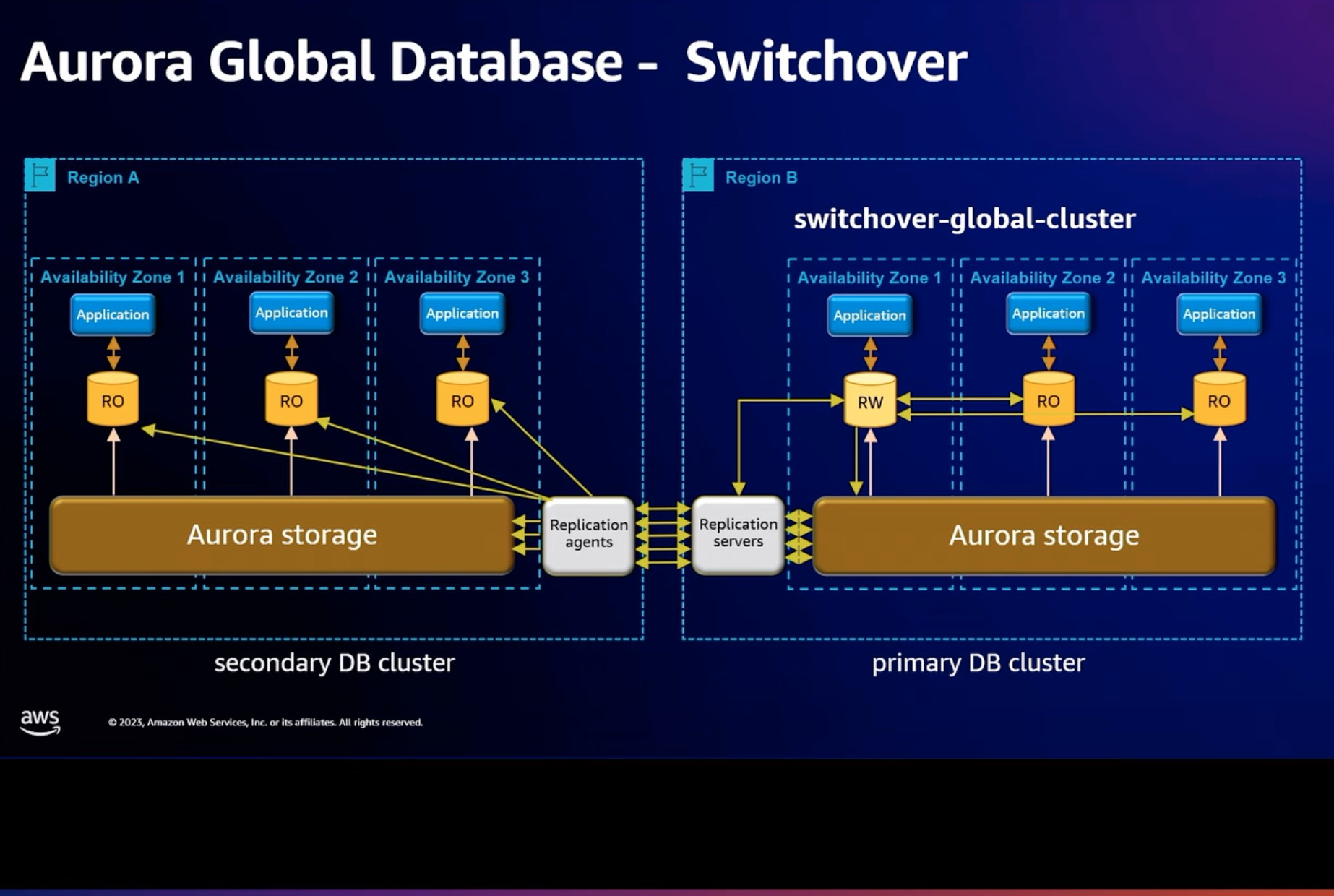
当然 Aurora 同时也保留原来的 Failover 的功能.
Aurora 跨 region 切换 RTO = 1~2 minutes. 切换过去以后, Region A 会重新和 Region B 建立主备关系, Region B 成为主 region, region A 成为 standby region.
并且这里 Region A 会在 crash 那个时刻打一个快照, 从而方便用户查询数据

Performance
在性能方面, Aurora 这次发布在计算节点增加本地NVEe SSD, 从而优化云存储 IO latency 带来的延迟. 在 PolarDB 里面已经有类似的能力, 叫 External BufferPool.
笔者观点:
现在的存储引擎InnoDB/RocksDB/ClickHouse 等待都是针对本地盘设计的存储引擎, 并没有针对云存储进行优化. 所以需要实现大量的IO 路径上面的优化减少云存储 latency 带来的影响. 具体可以看 CloudJump 这个文章.
另外, 笔者认为下一步的存储引擎应该会往云原生方面发展, 也就是存储引擎本身应该合理利用云上的 SSD/云存储/OSS 等待资源, 从而实现最好的性价比. 我们管这个叫 Cloud-Tier-Engine.
对于临时表通过本地NVMe Storage 进行加速
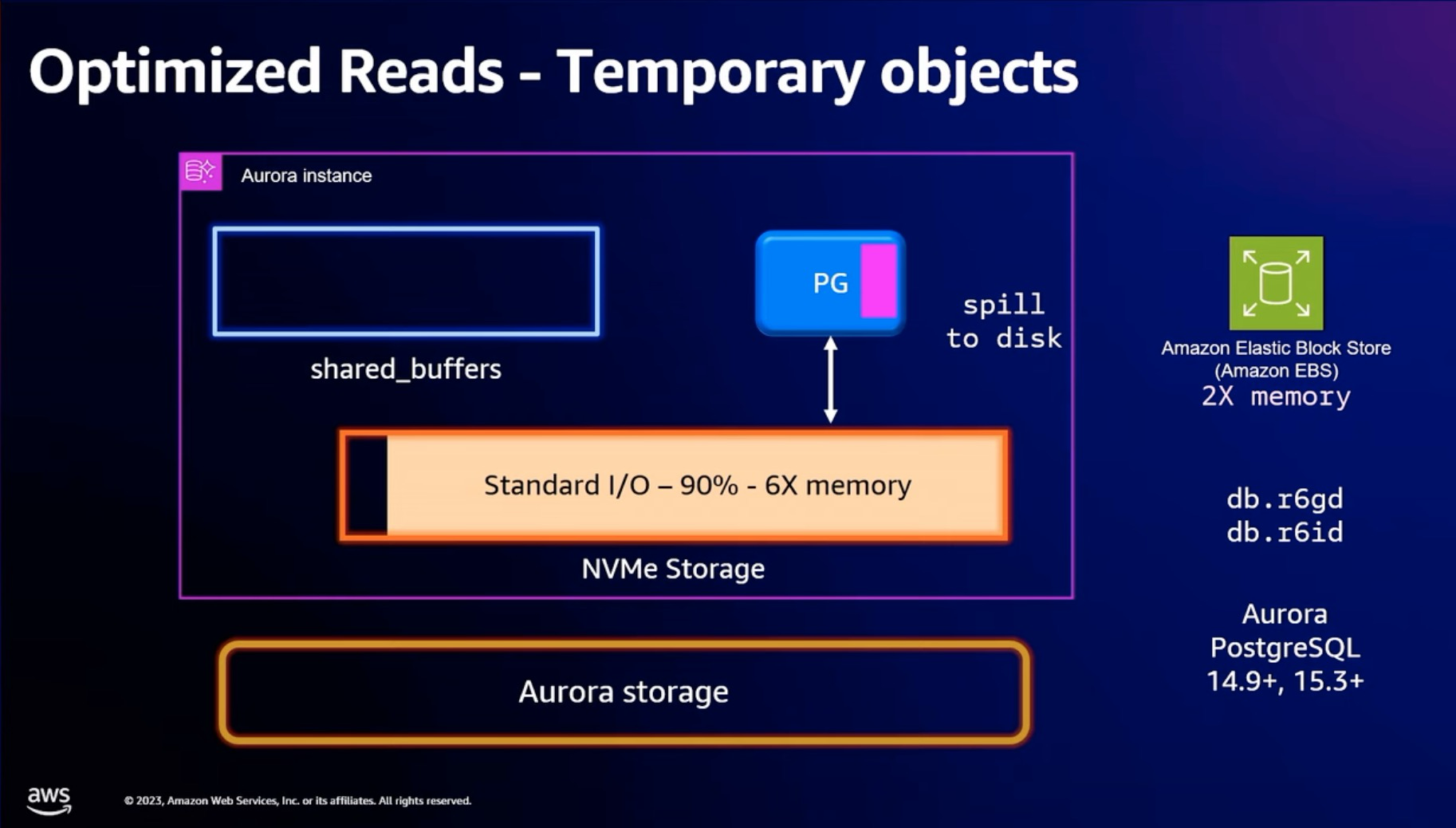
Tiered Cache 能力, 通过本地盘对Aurora storage 进行读加速
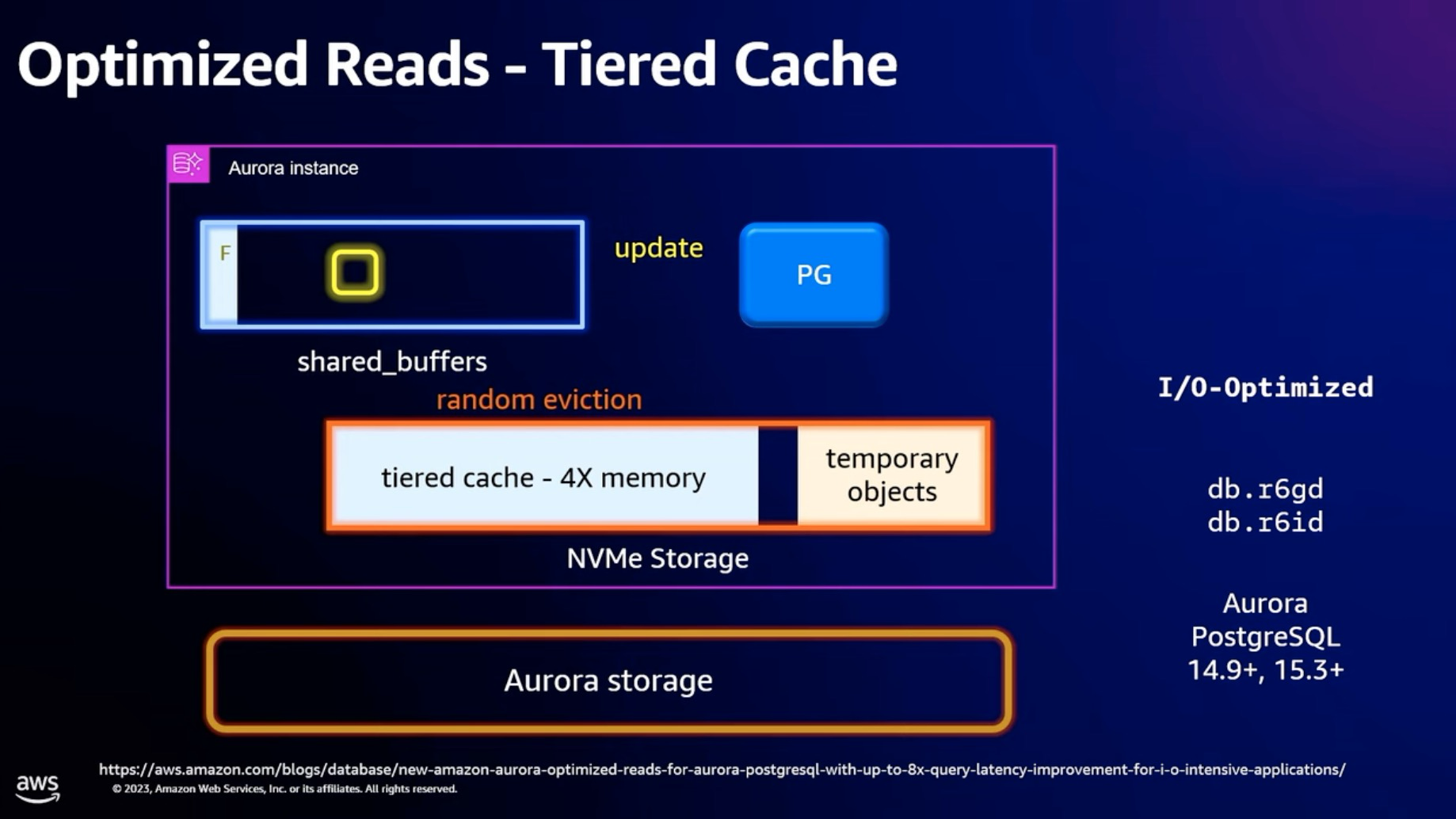
Tiered cache 流程是在 buffer pool 里面保留了一份tiered cache 的 MetaData, 读取的时候先检查 MetaData 里面有没有, 如果有直接从本地盘读取, 如果没有从 Aurora storage 读取.
那么什么时候往 tiered cache 里面写入内容呢?
和 external bufferpool 一样, 等这个 page 被 LRU list淘汰的时候(Page 不能是脏页), 并不是直接从内存中删除, 而是加入到 tiered cache 里面, 这里具体实现的时候要考虑 LRU list mutex 的开销了.
在读取的路径并不会主动去更新 tiered cache, 从而保证了读取性能.
Update 的时候也只需要更新 tiered cache 的 MetaData, 表示 tiered cache 里面的 page 是无用的就可以. 下次读取的时候, 就不会读取 tiered cache 里面的 Page.
那么 tiered cache 里面的内容如果做 LRU list 的淘汰呢?
这里Aurora 选择的测试是随机淘汰. PolarDB 的实现上则是根据 LRU 算法去选择合适的 Page 进行淘汰
存储计费能力
在存储能力方面, Aurora 终于发布了 Aurora I/O-Optimized. 直接按照磁盘空间大小进行计费, 原来的 Aurora I/O 的计费模式称为 Aurora Standard.
笔者观点:
Aurora 之前的存储计费模式一直被很多人诟病, 大部分的存储是按照磁盘空间大小收费, 而 Aurora 的存储按照磁盘空间以及 IOPS 进行收费, 导致用户使用的时候非常难以预估具体可能费用, 现在终于做出了改变.
